
La Network Visibility è alla base di una efficace strategia di protezione aziendale
Come possiamo difenderci da qualcosa che non riusciamo a vedere, misurare, analizzare? Anche se nel passato si è fatto ampio affidamento su soluzioni di sicurezza in grado di limitare le conseguenze di un attacco mediante contromisure statiche basate sulla scelta a priori di flussi di traffico ammessi (es. firewall) o di firme (es. antivirus), sappiamo bene che oggi questo approccio non è più adeguato. La complessità e la varietà degli attacchi che possono essere rivolti verso il patrimonio informativo di un’azienda ci obbligano ad analizzare con nuovi strumenti fenomeni che possono essere il risultato di più metodi (blended attack), che tendono ad agire senza far “rumore” nella massa di informazioni che viaggiano nelle reti (low and slow) e che sono spesso composti da più fasi apparentemente non correlate fra loro (staged attack). Se da un lato il progresso tecnologico rende disponibili strumenti estremamente potenti quali il Machine Learning e gli strumenti di Big Data Analysis, dall’altro cresce il rischio di collezionare volumi estremamente elevati di informazioni (con possibile rischio di esposizioni verso tematiche di violazione della privacy) senza che questi siano in grado di tradursi in dati significativi, numericamente gestibili, e quindi utili ai fini del riconoscimento, del contenimento e della reazione ad un attacco informatico.
Nel presente articolo verrà presentato un approccio alla tematica della visibilità di rete che nasce dall’esperienza reale di un operatore di telecomunicazioni e quindi dalla doppia esigenza di proteggere le informazioni sulla propria rete enterprise (intranet) al pari di qualsiasi grande azienda con decine di migliaia di utenti e di garantire il servizio in sicurezza sulla rete pubblica (internet) laddove gli utenti sono decine di milioni.
In merito all’obiettivo da porsi nell’effettuare un monitoraggio del traffico di una public network, il caso d’uso tipico è quello della protezione da attacchi di tipo DDoS (si veda in proposito l’articolo “La resilienza di una rete di telecomunicazioni ad attacchi di tipo DDoS” su questa testata), siano essi puramente volumetrici o applicativi. Nel caso di una rete enterprise gli obiettivi possono essere molteplici fra questi è possibile annoverare il riconoscimento di:
- un attacco di tipo DDoS;
- la propagazione di un malware;
- l’esecuzione di una scansione non autorizzata (passo propedeutico alla realizzazione di un attacco);
- la comunicazione con un sito di command and control;
- attività di data exfiltration;
- accesso improprio a risorse sulla rete;
- situazione anomala, non usuale e sconosciuta (da analizzare ulteriormente).
Dati gli obiettivi, il secondo passo da effettuare è definire che tipo di informazioni di base occorra prendere in considerazione. In particolare si presentano due possibilità: analizzare il traffico prendendone una copia integrale oppure analizzare descrittori sintetici dei “flow” di traffico in formati come Netflow (il più diffuso), NetStream, cFlowd, JFlow, sFlow ed IPFIX. La scelta tra i due approcci dovrà avvenire in base ai volumi di dati da analizzare, ai possibili impatti in termini di privacy e naturalmente all’effettiva utilità ed efficacia della fonte.
Il trade-off tra raccolta/analisi/archiviazione delle informazioni sul traffico (visibilità) e garanzie sulla appropriata gestione di queste informazioni (privacy) è un tema assolutamente di primo piano specialmente per chi si occupa di security su una public network.
| Cosa è il Netflow? Il NetFlow è una funzionalità originariamente introdotta da Cisco sui suoi router che offre la possibilità di analizzare e descrivere il traffico di rete IP quando attraverso una interfaccia, producendo un set di informazioni, che viene organizzato in record. Il Netflow si è evoluto partendo dalla sua prima versione (v1) resa disponibile già intorno al 1996, attraverso la versione 5, che ne ha segnato l’affermazione come standard de facto, fino alla versione 9 (IETF RFC3954) che ha introdotto il concetto di flessibilità nel formato del record, risultando adattabile a un maggior numero di contesti. Un flow, secondo la definizione dell’IETF, è: “una sequenza di pacchetti da un’applicazione mittente ad un’applicazione ricevente”; nell’ambito del Netflow viene considerato un flow ogni comunicazione unidirezionale identificata da 7 specifici campi degli header IP e UDP/TCP (definizione classica valida per v5), quindi ad un record vengono associati e conteggiati tutti i pacchetti che hanno in comune: indirizzo IP sorgente, indirizzo IP destinazione, porta sorgente, porta destinazione, protocollo, identificativo SNMP dell’interfaccia di ingresso, e valore dell’IP type of service (ToS). Queste però non sono le sole informazioni che possono essere esportate; molti altri dati possono essere resi disponibili, come: l’IP next-hop, identificativo SNMP dell’interfaccia di uscita, il numero di pacchetti associati al flow, il numero totale di bytes dei pacchetti associati al flow, l’uptime del sistema allo start del flow, l’uptime del sistema al momento dell’ultimo pacchetto associato al flow, informazioni sui TCP flags, l’Autonomous System number dell’IP sorgente, l’Autonomous System number (origin o peer) dell’IP destinazione, la prefix mask dell’IP sorgente, la prefix mask dell’IP destinazione ed altri ancora. Nessuna informazione sul payload dei pacchetti viene raccolta. I record, il cui tempo di permanenza nella memoria del nodo è regolato tramite alcuni parametri, vengono poi raggruppati ed esportati, utilizzando il protocollo UDP, verso i dispositivi destinati ad analizzarli indicati come ‘collector’. A seconda dello scenario di utilizzo il Netflow può essere campionato o meno (si parla appunto di sampled o unsampled Netflow); la differenza sta nel produrre/esportare informazioni solo su un campionamento di pacchetti o sulla loro totalità. Naturalmente a una maggiore quantità di informazioni (unsampled) corrispondono maggiori oneri computazionali (nella produzione/esportazione), elaborativi (nell’analisi) e di archiviazione. A questo proposito, due esempi agli estremi opposti sono da un lato quello del “billing”, dove è necessario tracciare tutti i pacchetti per una corretta tariffazione, e dall’altro quello della rilevazione di attacchi DDoS, dove è necessario potere analizzare grandi volumi di traffico ma le caratteristiche statistiche degli eventi sono tali da consentire un efficace uso del campionamento (passi di campionamento tra 1:1024 a 1:4096 sono i più utilizzati in questo ambito). In alcuni scenari per ragioni legate alla limitata capacità computazionale o funzionale di alcuni nodi, o alla loro obsolescenza, non è possibile attivare la generazione/esportazione del Netflow. In questi casi vengono utilizzati dispositivi esterni che svolgono questo compito: parliamo di tecnologie che ricevendo copia del traffico (raccolta tramite inserimento di ‘tap’ sui link, con l’utilizzo di SPAN/RSPAN o di network packet broker) e, senza archiviarlo in alcuno modo, si occupano di produrre ed esportare il Netflow. |
Nel caso di visibilità del traffico sulla rete Internet di un ISP la scelta è pressoché obbligata sia per i volumi in gioco (Terabit/secondo) che per le possibili problematiche relative alla salvaguardia della privacy dei clienti.
Per quanto riguarda la rete intranet, esistono sia soluzioni di mercato in grado di analizzare copia integrale del traffico sia soluzioni in grado di partire dal Netflow (preferibilmente non campionato per non rischiare trascurare fenomeni statisticamente rari). Nel primo caso è fondamentale porsi nell’ottica di realizzare un’analisi legata al rispetto della privacy degli utenti della rete siano essi interni o esterni all’organizzazione. Tale analisi (da ritenersi obbligatoria con l’entrata in vigore del GDPR General Data Protection Regulation nella forma di un PIA Privacy Impact Assessment) dovrà verificare se il rischio di trattare dati quali ad esempio URL di navigazione, email, file personali, etc…, sia commisurato alla finalità del trattamento (ovvero la protezione aziendale). Nel caso di utilizzo del Netflow come dato di base ai fini della visibilità, l’arricchimento dell’informazione con eventuali dati personali (ad esempio identificativo utente) avverrà solo in caso di gestione di evento classificabile come incidente di sicurezza limitando in maniera determinante il rischio di esposizione di dati personali.
Vale, infine, la pena di citare un ambiente che, viste le sue peculiarità, anche per la problematiche legate alla visibilità presenta delle esigenze specifiche: gli Internet Data Center (IDC). Questi presentano di fatto una commistione di caratteristiche di public e private network, inoltre, l’altissima densità delle infrastrutture di rete che vi sono concentrate, insieme all’utilizzo spinto di tecniche di virtualizzazione e di SDN (Software Defined Networking) richiedono anche per la traffic visibility soluzioni che siano adatte a questi ambienti.
La visibilità sulla rete pubblica di un ISP
Alla luce delle attuali minacce un ISP difficilmente può fare a meno di dotarsi di una o più piattaforme che gli diano visibilità dei flussi di traffico sulla sua public network; la vocazione security oriented di queste soluzioni, legata in primis alla DDoS Attacks and Traffic Anomaly Detection, non è la sola: sono strumenti in grado di dare supporto nelle analisi e nelle decisioni sia a chi si occupa di pianificazione delle reti, sia ai gruppi operativi. Più che in passato, infatti, possono scatenarsi in rete fenomeni rilevanti che sono direttamente connessi all’erogazione dei servizi offerti da attori esterni all’ISP, come gli OTT. Avere una visibilità di questi fenomeni tale da consentirne l’analisi e la gestione è di grande importanza.
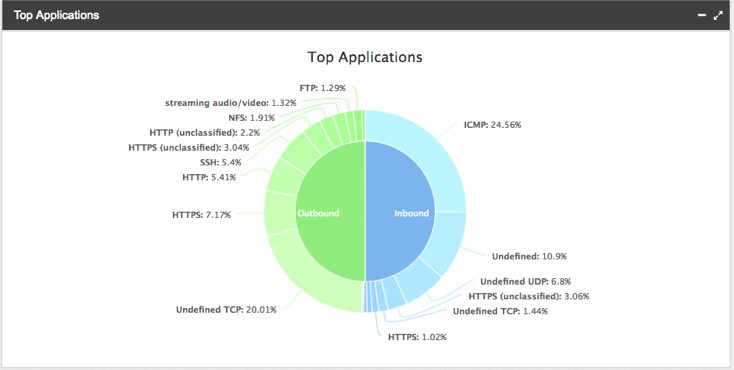
Le tecnologie utilizzate elaborano principalmente sampled Netflow (visti i volumi di traffico in gioco), ma anche informazioni come gli indicatori di utilizzo delle interfacce dei nodi, i dati del piano di controllo della rete (BGP), le query eseguite sui DNS e dei feed esterni che consentono di avere una visione continuamente aggiornata delle architetture di player come gli OTT e le grandi piattaforme di content delivery.
L’analisi dei pattern di traffico, correlata alla tipologia di risorse con cui viene scambiato e alla variabilità dei profili di traffico nel tempo, consente di rilevare anche potenziali anomalie e utilizzi fraudolenti della rete.
Le attività di real-time monitoring precedono e accompagnano l’utilizzo di altre componenti dedicate al contrasto degli attacchi: l’analisi dell’andamento del traffico relativo alle risorse per cui le piattaforme generano alert e allarmi, permette di attivare le componenti di mitigation e di coordinare le attività di contrasto agli attacchi e ripristino delle normali condizioni di funzionamento della rete. In war time è rilevante anche la capacità di tenere sotto controllo l’evoluzione dei fenomeni che si gestiscono, adattando le contromisure in tempi rapidi e nel modo ottimale.
Per rappresentare semplicemente alcune potenzialità di queste tecnologie possiamo fare degli esempi, partendo dalla capacità di dare, a valle della rilevazione di un attacco DDoS, anche graficamente una indicazione in real-time sui vari vettori di cui questo è composto:
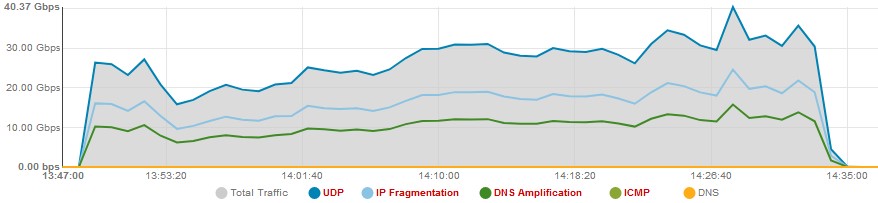
Una vasta gamma di informazioni circa il traffico di attacco viene resa disponibile in tempo reale, tra queste: volume, durata, distribuzione geografica delle sorgenti, dimensioni e caratteristiche (TCP Flag) dei pacchetti.
Per quanto riguarda gli aspetti non strettamente security related, è interessante osservare, come esempi, due fenomeni che senza le piattaforme di cui trattiamo non sarebbero stati rilevati e che riguardano eventi del recente passato: il matrimonio del principe William con Kate Middleton (29 aprile 2011) e il rilascio della release 9 dell’Apple IOS (17 settembre 2015).
Nel primo caso, a causa dell’elevatissimo numero di utenti che ha seguito l’evento in streaming, è stata osservata una quantità di traffico associato a porta/protocollo usati da Macromedia Flash con un picco di circa quattro volte il valore di norma osservato sulla rete in oggetto per quella porta/protocollo.
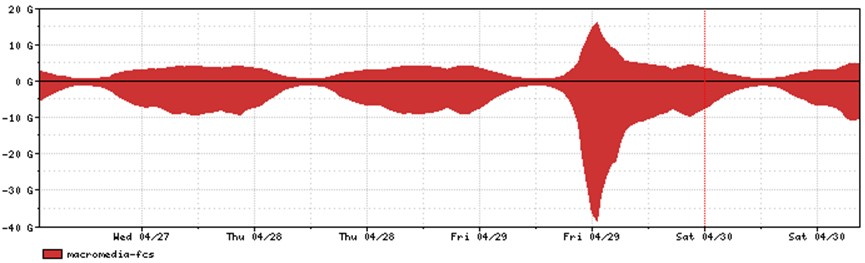
Nel secondo caso quando è stata rilasciata la versione 9 dell’Apple IOS, in breve tempo, un elevatissimo numero di dispositivi ne ha effettuato il download: questo ha portato ad un aumento di oltre 100Gbps di picco nel traffico scambiato tra la rete in oggetto ed un altro Autonomous System, che è quello che ospitava la piattaforma di distribuzione utilizzata da Apple.

La visibilità sulla rete intranet di una enterprise
L’approccio tradizionale per proteggere una rete intranet aziendale è quello di agire sul suo perimetro: in particolare viene analizzato il traffico sul confine tra la rete interna all’azienda (che ospita infrastruttura e sistemi) ed il mondo esterno (internet) tramite i tradizionali strumenti di sicurezza perimetrale quali firewall, sonde, proxy ecc..
Questi strumenti sono in grado di generare un numero elevato di allarmi, dati e statistiche, principalmente sulla base di meccanismi deterministici come il superamento di una soglia o il riconoscimento di una firma che, dunque, devono essere analizzati a fondo per discriminare gli eventi realmente malevoli dai falsi positivi: quando si riesce ad individuare una traccia, molto spesso l’attacco è già stato portato a termine.
Siccome l’obiettivo dei professionisti della security è riconoscere le potenziali minacce prima che queste abbiano effettivamente luogo, si fa sempre più forte la necessità di strumenti di security che, tramite algoritmi di analisi statistica e Machine Learning, siano in grado di analizzare velocemente grandi quantità di dati per individuare anomalie nel comportamento degli utenti e del traffico da essi generato, che possono essere ricondotte ad eventi effettivamente malevoli.
Inoltre, potrebbe non essere più sufficiente limitarsi a registrare gli eventi e gli allarmi generati sul confine della rete, perché sempre più spesso le azioni malevole, intenzionali o non, hanno origine proprio all’interno della rete aziendale, ad opera ad esempio di un insider, un utente che è riuscito a penetrare le difese perimetrali con l’obiettivo di diffondere un malware, avere accesso a dati sensibili o comunicare con un centro di Comando e Controllo.
Spesso la visibilità che si ha della propria rete è limitata, soprattutto nel caso di infrastrutture cresciute in dimensione e volumi di traffico nel corso degli anni. In questo modo le attività malevoli di un insider o di postazioni di lavoro compromesse possono essere portate avanti per molto tempo senza essere rivelate.
Per rispondere a tali esigenze le aziende possono dotarsi di una nuova classe di prodotti chiamati UEBA (User and Entity Behavior Analysis), che fanno della visibilità della rete un vero e proprio strumento di security, grazie alla possibilità di determinare dinamicamente la baseline di traffico per riconoscere e gestire real-time le diverse attività malevole che possono occorrere all’interno della rete.
I sistemi UEBA sono architetturalmente complessi, in quanto basati su diversi elementi distribuiti capillarmente all’interno della rete aventi lo scopo di raccogliere informazioni sul traffico sotto forma di descrittori (Netflow), informazioni non strutturate come log di web proxy, di sistemi di autenticazione centralizzati, query DNS, o addirittura una copia integrale del traffico, che devono essere raccolti da collettori per poter essere analizzati.
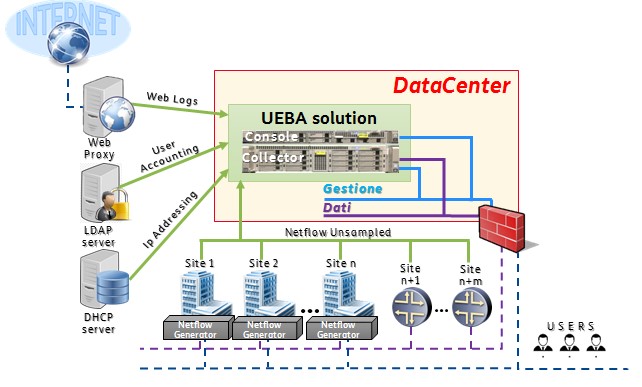
Sulla base di questi dati viene dunque costruito un vero e proprio modello della rete, in termini di volumi e tipologie di traffico, con lo scopo di definire il comportamento “normale” di gruppi omogenei di utenti, cioè persone ed entità che all’interno dell’azienda ricoprono i medesimi ruoli da cui è lecito aspettarsi un comportamento simile, e di conseguenza individuare tempestivamente le eventuali deviazioni potenzialmente “malevole” dal modello normale.
L’obiettivo dichiarato dei sistemi UEBA è dunque quello di accorciare i tempi di rilevazione, diminuendo il mean time to detect (MTTD) di attività malevole, volontarie o riconducibili a dispositivi compromessi, che avvengono all’interno della rete. Questi sistemi permettono inoltre di gestire efficientemente l’analisi forense di tali eventi, in quanto sono in grado di storicizzare i dati raccolti per lunghi periodi, e renderli disponibili per permettere l’estrazione informazioni di valore relativi agli attacchi.
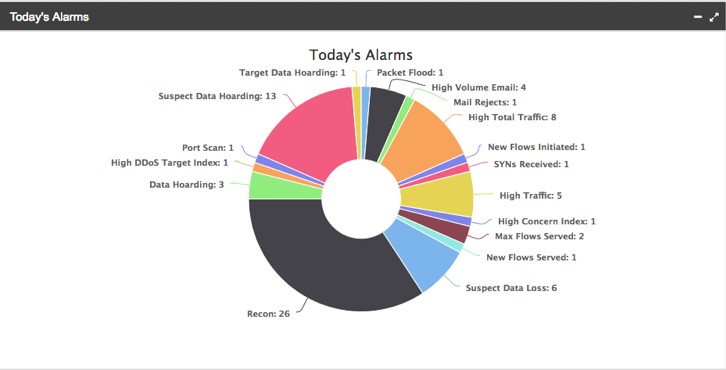
Il grado di interazione tra i sistemi UEBA e l’ecosistema dei prodotti tradizionali di sicurezza in campo è un fattore di successo della soluzione di visibility. Da un lato, questi possono essere usati come sorgenti per i dati necessari alla generazione delle baseline comportamentali, dall’altro gli stessi strumenti possono essere innescati nella gestione degli incidenti di sicurezza rilevati, in modo automatico nel caso di azioni di remediation o in modo manuale, ad esempio per attività di follow-up ed analisi forense.
A titolo di esempio possono essere citati i sistemi di autenticazione (Active Directory o Radius server) attraverso i quali è possibile ottenere informazioni sull’attività di un utente, ma che allo stesso tempo possono essere usati per inibire rapidamente ed in modo automatico l’accesso di un utente o sistema su determinati asset, per limitarne il perimetro di azione e/o per bloccare la diffusione di un malware.
Un medesimo meccanismo di interazione si può avere con i Proxy, le sonde IPS ed i server DNS che forniscono dati collaterali, che possono cioè arricchire il livello di dettaglio dei dati in possesso del sistema UEBA e che possono essere istruiti in maniera automatica per bloccare i flussi di traffico di un indirizzo IP coinvolto in un evento di sicurezza.
Le informazioni sugli allarmi scattati ed i relativi dettagli possono essere, quindi, inviati verso il SIEM (Security Information and Event Management) per supportare le successive attività di analisi forense e verso i prodotti di Threat Intelligence che avranno il ruolo di generare degli indicatori di compromissione (IoC) che, al tempo stesso, possono essere usati come dataset di informazioni che i prodotti UEBA sono in grado di elaborare.
La visibilità: un fattore chiave
La disamina proposta ha tentato di porre in evidenza le ragioni che fanno della visibilità una fattore chiave nello scenario attuale per proteggere, gestire e sviluppare le reti.
L’evolversi delle minacce, insieme alla complessità dei moderni ambienti ICT non consentono di prescindere dall’adozione di strumenti utili ad avere informazioni precise ed aggiornate su quello che accade, nonché dal dedicare la necessaria attenzione alla progettazione di architetture che considerino in modo nativo le esigenze legate alla visibilità.
A cura di: Giuseppe Giannini e Alessandro Patacca

L’Ing. Giuseppe Giannini lavora su temi legati alla network security nel gruppo Telecom Italia dal 2003; si occupa della definizione di soluzioni e progettazione di piattaforme per la sicurezza del backbone IP e della rete corporate di TIM, con un focus sugli attacchi DDoS e le anomalie di traffico. Ha maturato una ampia esperienza su architetture di rete fixed/mobile e sulla protezione di infrastrutture critiche; ha svolto attività di network security assessment presso consociate estere. È membro dell’ETNO CERT Task Force come DDOS Expert per TIM.

Alessandro Patacca è un Ingegnere informatico che si occupa di network security in TIM dal 2016. Si occupa dell’ingegnerizzazione di piattaforme per la sicurezza della rete corporate e per la protezione DDoS degli Internet Datacenter di TIM. Ha un forte interesse per i temi legati alla virtualizzazione e alle tecnologie DevOps.





