Java Secure Coding – garantire la sicurezza delle applicazioni (web)
Ideare, costruire e realizzare codice sorgente sicuro è un’esigenza fondamentale per analisti, progettisti e sviluppatori: rappresenta una priorità assoluta ancor più rilevante all’interno dei contesti di deploy su architetture web, distribuite e in-cloud, ove sussistono forti temi come data protection, multi-tenancy, dipendenze da librerie di terze parti, necessità di arrivare a profili di responsabilità condivisa.
I linguaggi di programmazione moderni, seppur con caratteristiche e funzionalità differenti, offrono agli sviluppatori librerie standard, frameworks e containers ideati per consentire l’applicazione di un ampio set di regole di secure programming: tali costrutti, tuttavia, non garantiscono automaticamente la possibilità di arrivare alla produzione di codice sicuro, per il solo fatto che vengano utilizzati all’interno delle applicazioni.
A pervasive way of thinking
Il secure coding può essere costruito già dal punto di vista architetturale e progettuale nella propria applicazione, o singolo modulo software, ben prima di scrivere una sola riga di codice sorgente. A partire dall’obiettivo essenziale di evitare vulnerabilità occulte nel proprio codice, nonché prevenire attacchi da parte di hackers umani e/o malevoli sistemi automatizzati, lo sviluppatore Java deve considerare il proprio applicativo dalla prospettiva di interazione di una moltitudine di elementi soggetti a potenziali vulnerabilità: ambiente di deploy e application server, JVM, moduli funzionali considerati sia singolarmente che dopo l’assemblaggio, eventuali librerie esterne, connettori, file system.
È chiaro che definire un perimetro di prevenzione e reazione non rappresenti una attività da sottovalutare, tanto più che le caratteristiche di linguaggio a oggetti realizzano uno scenario OOP in cui le entità si scambiano messaggi, e in base ad essi mutano stato e caratteristiche, definendo un contesto di elevata dinamicità e variabilità dovute agli stimoli esterni.
La strategia di Java Secure Coding universalmente costruita negli anni è arrivata a identificare accademicamente oltre 18 ambiti di applicazione strategica di costrutti e regole. Lo scopo di uno standard di secure coding è promuovere la sicurezza del software: tuttavia, a causa della relazione tra la sicurezza e altri attributi di sistema come ad esempio portabilità e prestazioni, gli standard di codifica possono includere requisiti e raccomandazioni che si occupano principalmente di altri attributi di sistema che hanno anche un impatto significativo sulla sicurezza. Arrivare a un vero e proprio standard di secure coding, insomma, negli anni si è dimostrata procedura complessa e, di fatto, le good practices attualmente consigliate rappresentano un equo compromesso tra tutti gli attributi che influenzano la qualità di un software.

Di seguito si propongono alcuni spunti, seppur non esaustivi, correlati ad alcuni contesti molto diffusi e spesso sfruttati per violare – con ben poco effort peraltro – le applicazioni web basate su architettura Java.
Input Validation
La validazione dell’input è tra i più rilevanti tra i numerosi criteri da considerare, significativo per tutte quelle applicazioni che richiedono l’inserimento di dati diretto da view oppure da altre sorgenti esterne all’applicazione. Criterio da applicare soprattutto in applicativi multilivello, per cui nello strato DAO (Data Access Object) vi è un connettore bidirezionale con un database di tipo relazionale, destinato a ricevere istruzioni in SQL. Parallelamente a input validation spesso è affiancata algoritmica di Data Sanitization, per cui da flussi di input (manuali o dataset strutturati) vengono rimossi elementi sensitivi come informazioni personali, confidenziali, o che portino alla identificazione di soggetti privati o giuridici.
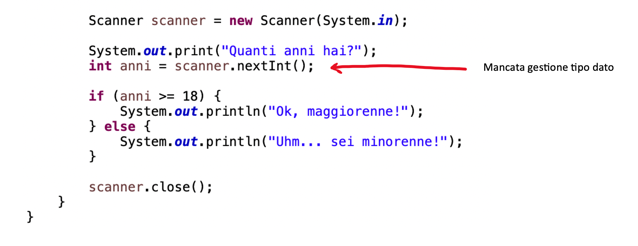
Un banale esempio di errata validazione dell’input può essere il seguente snippet, ove l’acquisizione di una variabile dall’utente non è blindata con un controllo sulla corretta tipizzazione:
Grazie alla sua indipendenza della piattaforma, flessibilità e bassa complessità, il linguaggio di markup XML ha trovato uso in applicazioni che vanno dalle chiamate di procedure remote allo storage, allo scambio e al recupero dei dati. Tuttavia, a causa della sua versatilità, XML è vulnerabile a un ampio spettro di attacchi. Il noto XML-injection si verifica quando un utente che ha la capacità di fornire XML strutturato come input può ignorare il contenuto di un documento XML iniettando tag XML nei campi dati. Questi tag vengono interpretati e classificati da un parser XML come contenuto eseguibile e, di conseguenza, possono causare l’overriding di alcuni membri dei dati.
Si consideri il seguente esempio, evidenza di una mancata validazione dell’input utente.

Tramite un modulo di creazione utente, a cui è riuscito ad ottenere accesso, l’attaccante immette i seguenti dati.
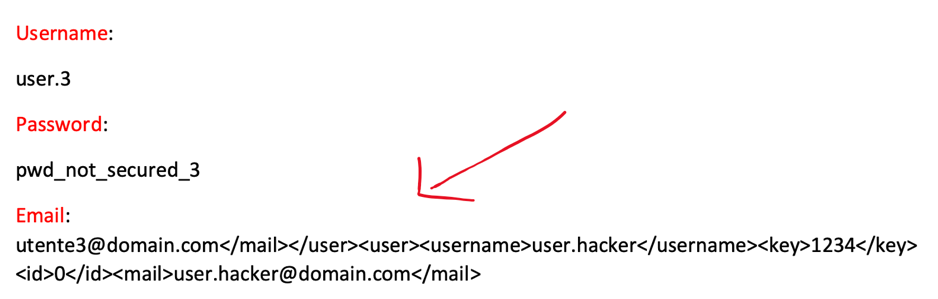
Il risultato nell’xml generato, formattato, e che è un componente chiave per l’autenticazione è il seguente.

Essendo XML un linguaggio interpretato sequenzialmente e avendo l’attaccante usato una id 0 che, anche se presente sarà sovrascritta dalla nuova istruzione, potrà entrare con le proprie credenziali.
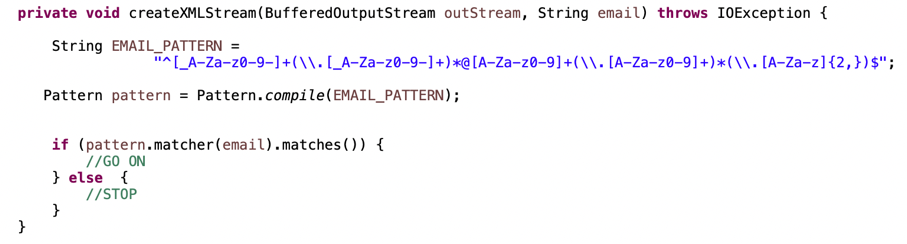
Chiaramente, la mancanza di validazione sul campo email permette l’injection di valori e caratteri speciali in grado di alterare la semantica del file xml di configurazione, una volta che l’attaccante ha intuito l’utilizzo di tale meccanismo per il login a livello applicativo.
A seconda dei dati specifici e dell’interprete o del parser di comando a cui vengono inviati i dati, devono essere utilizzati metodi appropriati per disinfettare l’input dell’utente non attendibile. Una possibile soluzione nel contesto descritto è l’utilizzo della classe Pattern come validatore di formato, come mostrato nello snippet seguente.
Exception handling
La gestione delle eccezioni rappresenta un altro contesto chiave per il secure coding in Java. Uno degli errori più frequenti, soprattutto in ambito web-app, è non considerare che eventuali stack traces generati da exceptions specifiche e mostrati nel browser (a causa di mancato settaggio di error pages di default, ad esempio) rappresentano un punto di ingresso per eventuali malintenzionati, in quanto vanno a esplicitare caratteristiche tecniche del codice su cui l’applicativo è basato.
Si consideri il seguente stack trace, formattato di default dall’application/web server a partire da una situazione anomala generatasi in una jsp page in deploy su Apache Tomcat:
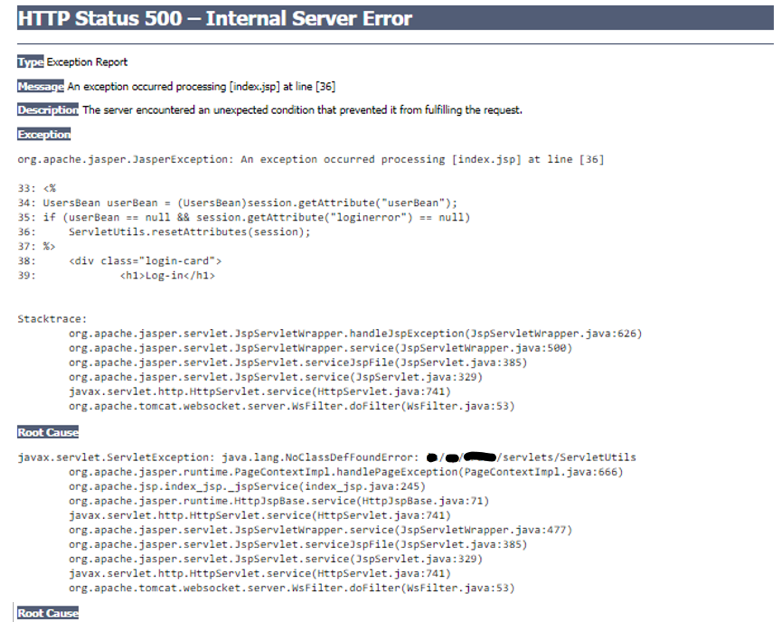
Le informazioni strutturali che emergono dalla pagina, formattata in modo intelligibile a chiunque via browser ne abbia accesso, riportano caratteristiche tecniche potenzialmente attaccabili:
- la pagina usa un attributo di sessione, “userBean”;
- vi è una autenticazione session-based;
- nella struttura dell’applicativo sussiste una classe denominata “ServletUtils” collocata in “nomepakage/servlets/” al cui interno potrebbero essere presenti informazioni correlate al login;
- la web app utilizza uno strato di controller basato su servlets.
Il target per un potenziale attaccante, in tal caso, potrebbe essere quello di sfruttare tali informazioni strutturali – ottenute anche solo a causa della mancanza di una error-page di default – per bypassare l’autenticazione agendo sugli attributi di session (session hijacking/fixation), lavorando su path exploit, o sfruttando note vulnerabilità correlate all’architettura a servlet.
Il principio base di secure qui coding violato è riferibile all’assenza di un fail-safe mechanism che permetta all’applicazione, nella sua espressione via browser, di funzionare correttamente anche in tale situazione, qualunque ne sia la causa. Pianificando e gestendo le eccezioni, gli sviluppatori devono implementare meccanismi di fallbacks, decadimento parziale o percorsi logici alternativi per garantire che l’applicazione continui a funzionare in modo sicuro in condizioni anomale, dovute a input errati o situazioni sistemistiche contingenti.
In che fase dello stack dello sviluppo software ricade tale attività? Intercettare già in fase di progettazione possibili situazioni anomale è spesso auspicabile, seppur guidi alla ricerca di soluzioni generiche che possano fungere da percorso alternativo per qualunque eccezione. Ad esempio, in una web-app Java based, settare una error-page di default con indicazioni di view generiche come “il sistema non è disponibile, riprovare”, oppure “contattare l’amministratore”, consente di coprire qualunque casistica di errore possibile, andando eventualmente a includere più percorsi (cioè, error-pages) specifici in base a determinati errori, qualora ve ne fosse la necessità senza mettere a rischio la sicurezza dell’applicazione o dei sistemi su cui è in deploy (principio di minima informazione necessaria per l’utente).
Serialization & Data Sanitization
La serializzazione Java è un processo di conversione di un oggetto logico (OOP) in un flusso di byte, che può essere reso persistente o immediatamente trasmesso sulla rete, e successivamente ricostruito nella sua forma originale grazie a un processo detto di de-serializzazione.
I vantaggi di tale tecnica, se usata sapientemente, sono notevoli. Essa permette di salvare lo stato di un oggetto in un dato istante del ciclo di vita dell’applicazione generandone una rappresentazione binaria, trasmetterlo a un altro contesto e ricostruirlo garantendo sincronizzazione e coerenza logica. Spesso utilizzata anche per garantire autenticità a specifici moduli funzionali, può portare a miglioramenti prestazionali dovuti proprio alla disponibilità di strutture logiche trasmissibili o recuperabili in uno stato che, ricreato da 0, richiederebbe tempi di calcolo elevati.
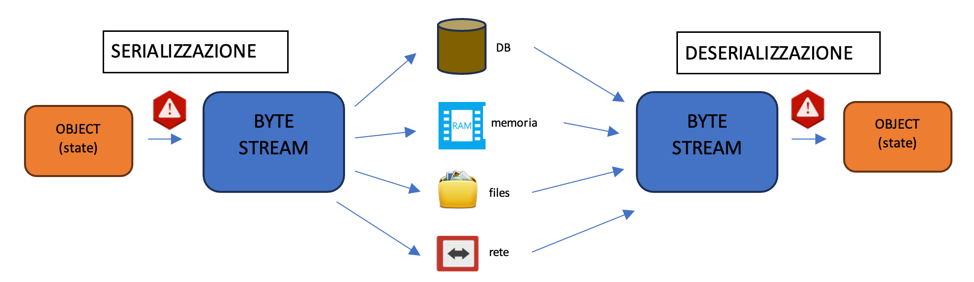
Proprio a causa dell’ampio utilizzo che se ne ritrova in applicazioni anche critiche, rappresenta uno dei contesti più vulnerabili del linguaggio in quanto relativamente semplice da implementare e applicabile a una moltitudine di scenari, anche grazie alle caratteristiche di indipendenza dalla JVM.
Consideriamo, ad esempio, la vulnerabilità nota con il nome di “Serialization Protocol Injection”. Se il processo di deserializzazione non include esplicitamente nel codice tecniche di validazione o controllo dell’integrità dell’output, è teoricamente possibile inserire all’interno del binario serializzato informazioni ad hoc o addirittura codice eseguibile. È pur vero che, in ambiente Java, essendo il serializzato un binario, rispetto ad altri linguaggi l’injection di bit al suo interno risulti più difficoltoso, ma il fattore di rischio esiste. Una volta che l’aggressore può controllare i dati consolidati in fase di serializzazione e successivamente ricostruiti, può di fatto controllare gli oggetti dell’applicazione e le variabili in memoria, influenzando il flusso del codice all’interno dello stack creando alterazioni significative nel comportamento dell’applicazione, anche su specifici moduli critici (es. MFA e persistenza degli oggetti user di sessione).
Un aiuto in tale scenario può arrivare da particolari tecniche di serializzazione che includano by design la necessità di validare l’oggetto ricostruito; è il caso di OWASP Java Encoder (rif. Spring Security), particolarmente utile in contesti web (ove la serializzazione è di ampio impiego) e che sfrutta una tecnica denominata Contextual Output Encoding, in grado di limitare il rischio di Cross-Site Scripting (XSS). Tale tecnica implica la codifica di dati generati dall’utente, o non attendibili, prima di trasformarli in HTML, JavaScript, CSS o altri contesti per assicurare che i caratteri speciali vengano trattati come dati anziché come codice eseguibile. In abbinamento alla deserializzazione, l’utilizzo di COE permette di escludere la possibilità che nel binario da ricostruire siano inclusi caratteri speciali che possano essere utilizzati per alterarne il contenuto, realizzando effettiva data sanitization.
Secure Database Access
La comunicazione con strati database (DAO) in ambiente Java – ma anche in qualunque altro linguaggio di alto livello – include aspetti cruciali in termini di secure code, in quanto va a integrare entità software distinte, ognuna con regole e semantiche specifiche. È necessario considerare l’adozione di best practices per la protezione dalle minacce alla sicurezza diffuse come SQL injection e l’accesso non autorizzato, a seguito di appropriazione delle credenziali memorizzate in struttura inopportuna.
L’utilizzo di query parametrizzate è un costrutto base fornito dal linguaggio e, qualora non si utilizzino framework che mettano a disposizione meccanismi differenti (es. Hibernate), è da preferire a tecniche che prevedano concatenazione di stringhe tramite segnaposto.

In un’applicazione web Java, le prestazioni e la sicurezza sono strettamente correlate: load testing, la messa a punto delle prestazioni e l’utilizzo di algoritmi di memory caching possono aiutare a ottimizzare le prestazioni e migliorare la sicurezza complessiva. Parallelamente, frequenti audit di sicurezza e aggiornamento delle librerie di terze parti con le ultime patch di sicurezza, applicazione di best practices e verifica puntuale delle caratteristiche dell’environment su cui la web app è in deploy.
Si consideri, ad esempio, una applicazione multilivello che sovraccarica il server database a causa di ripetute richieste di connessione passa in uno stato inconsistente molto rapidamente, soprattutto se non sono state previste contromisure a un banale attacco DDos: il pooling delle connessioni, per gestire e riutilizzare le connessioni al database in modo efficiente, aiuta a prevenire l’esaurimento delle risorse e migliora le prestazioni riutilizzando le connessioni esistenti. La libreria Apache Commons DBCP (Database Connection Pooling) fornisce costrutti interessanti per mettere a punto by design un sistema di pooling da utilizzare in qualunque modulo applicativo di livello DAO.

Nella porzione di codice sopra riportata si può notare come il metodo instauri una connessione al DB tramite un utente specifico, preventivamente dotato degli opportuni privilegi e di norma impostati secondo il noto criterio di Least privilege. Poiché la connessione al server DB in architetture relazionali è necessaria per lo scambio di informazioni bidirezionali, un efficace criterio di sicurezza consiste nell’implementare una tecnica di RBAC (role-based access control), forzando un layer di controllo di accesso ulteriore.
La role-based auth può essere realizzata sia a livello DB (preventivamente, agendo su tabelle create ad hoc), sia a livello applicativo creando un servizio di autorizzazione utente che tenga conto della relativa classe di privilegio.

Attenzione al logging
Per ultimo, ma non meno importante, un cenno all’utilizzo di sistemi o moduli di logging, creati ad hoc o di terze parti. Il controllo puntuale sul ciclo di vita run-time dell’applicazione e il tracciamento dello stato degli oggetti comunicanti risulta importante per intercettare eventuali anomalie o per rilevare specifiche azioni degli utenti.
L’utilizzo del logging di norma prevede l’introduzione di un ulteriore layer di persistenza in cui conservare le informazioni di tracciamento, su file system o su database, e in alcuni casi può essere utile anche la trasmissione immediata dei messaggi di log via protocollo e-mail o TCP/IP. Alcuni frameworks come SLF4j o Log4j forniscono costrutti pronti all’uso o di facile customizzazione, ma è importante rilevare che nel corso degli anni vi sono stati degli episodi di vulnerabilità all’interno delle applicazioni che ne facevano uso. Si tratta generalmente di un errato utilizzo delle best practices di implementazione, ma nel caso di Log4j, ad esempio, sono in archivio scoperte di vulnerabilità significative, come la nota “Log4Shell” occorsa a inizio 2022. Nel report ufficiale della CISA (Cybersecurity and Infrastructure Security Agency), che indicava le funzionalità JNDI incluse in Log4j come principale responsabile, è spiegato che un attaccante poteva sfruttare Log4Shell inviando una richiesta appositamente strutturata a un sistema vulnerabile, causando l’esecuzione di codice arbitrario application-level. L’avversario può quindi rubare informazioni, lanciare ransomware o condurre altre attività dannose. Premesso che l’utilizzo di tali librerie è assolutamente preferibile rispetto a costrutti from scratch, in quanto consolidate dalla comunità, funzionalmente complete ed efficaci, come può lo sviluppatore proteggersi da tali vulnerabilità? La risposta è la stessa per qualunque tipo di libreria esterna utilizzata nel proprio source code, ovvero in presenza di risorse di terze parti nel proprio codice è necessario monitorare costantemente i repositories ufficiali in termini di aggiornamenti e knowledge base.
Nel caso di Log4Shell, l’aggiornamento immediato a Log4j versione 2.15.0 o successive correggeva la vulnerabilità riscontrata a fine 2021/inizio 2022, avendo cura di implementare nel proprio codice, per un tempo significativo, algoritmi di monitoring al fine di assicurarsi l’effettiva efficacia della soluzione.

References
- The Cert® Oracle Secure Coding Standard For Java, Addison-Wesley
- Pro Spring Security: Securing Spring Framework 6 and Boot 3-based Java Applications, Apress
- Oracle, https://www.oracle.com/it/java/
Articolo a cura di Igor Serraino

Igor Serraino è professionista IT.
Opera come analista infrastrutturale e di Open Innovation nel contesto di Impresa 4.0 fin dal 2017, in qualità di Technology Expert per una importante società di settore attiva in ambiti aziendali eterogenei e sfidanti.
Il suo portfolio professionale senior-level si consolida attraverso una decennale esperienza da analista e sviluppatore hard-skills in ambienti Java-based, con particolare riferimento alla coprogettazione e sviluppo di applicativi per la gestione finanziaria commercializzati nel mondo della Pubblica Amministrazione.
Ha all’attivo numerose attività di formazione aziendale, workshops e pubblicazioni nei contesti di Cyber Security (GDPR e ISO27001), Legal-Tech, BlockChain Architect.