

Intelligenza Artificiale Privacy Preserving: un Futuro per la Protezione dei Dati Sensibili
Durante il 22° Forum ICT Security, Manuel Roveri – Professore Ordinario presso il Politecnico di Milano e Co-founder di Dhiria s.r.l. – ha esplorato le prospettive future dell’Intelligenza Artificiale Privacy Preserving, con particolare enfasi sulle tecnologie emergenti per la tutela delle informazioni personali e aziendali.
Nella relazione “Machine Learning e Homomorphic Encryption: Il Futuro dell’Intelligenza Artificiale Privacy Preserving”, il prof. Roveri ha delineato le principali sfide connesse all’implementazione dei servizi AI e al necessario bilanciamento con la tutela della privacy: ha poi illustrato tecniche di privacy-preserving computation, tra cui l’anonimizzazione e l’homomorphic encryption, fornendo esempi concreti di applicazioni ai dati genomici e satellitari.
Tra i temi affrontati anche le sfide del deep learning su dati criptati e relative potenzialità di addestramento, nonché l’importanza cruciale della privacy in tutti i servizi AI; l’obiettivo principale resta infatti garantire la riservatezza delle informazioni, tramite tecniche sofisticate di elaborazione sicura su dati criptati.
L’intervento ha evidenziato come le tecnologie emergenti possano consentire risultati avanzati senza compromettere la riservatezza delle informazioni sensibili, aprendo la strada a un futuro in cui l’intelligenza artificiale rispetti integralmente la privacy degli utenti.
Guarda la video registrazione completa dell’intervento:
Contesto dell’Intelligenza Artificiale Privacy Preserving
Negli ultimi tempi l’intelligenza artificiale ha subito un’evoluzione sostanziale, segnata dal cambiamento radicale avvenuto all’inizio dello scorso anno.
Tale evoluzione è stata agevolata dalla disponibilità di modelli di linguaggio di grandi dimensioni: come GPT-3, sviluppato già nel 2017 e utilizzato nel 2020 per la redazione di un articolo pubblicato dal quotidiano britannico Guardian.
La svolta avvenuta nel 2023 ha riguardato il modo in cui l’AI è diventata accessibile a un pubblico molto più ampio. Se infatti nel passato l’implementazione di questi algoritmi richiedeva un team di esperti di AI, dataset su larga scala e infrastrutture di calcolo avanzate, oggi le stesse capacità sono disponibili per chiunque grazie alla diffusione dell’Artificial Intelligence-as-a-Service (AIaaS).
Analogamente ad altri servizi digitali – come quelli di posta elettronica, archiviazione, CRM – l’AIaaS non esige che l’utente comprenda l’algoritmo sottostante o l’infrastruttura su cui opera: per ottenere i risultati è sufficiente collegarsi al servizio tramite dispositivi mobili o browser e fornire i dati richiesti.
Tuttavia il relatore ha ricordato che l’uso di questi servizi, per quanto spesso gratuiti, comporta dei costi impliciti poiché implica il rilascio di dati in chiaro, imponendo un compromesso tra la comodità dei servizi e la protezione della privacy.
Pertanto, il prof. Roveri ha posto una domanda fondamentale: come progettare servizi di intelligenza artificiale che preservino la privacy dei dati?
Tecniche fondamentali per l’Intelligenza Artificiale Privacy Preserving
La Privacy Preserving Computation affronta questo problema mediante diverse tecniche che garantiscono la riservatezza dei dati durante il processo di elaborazione.
Tra tali tecniche, il relatore ha sintetizzato le principali:
-
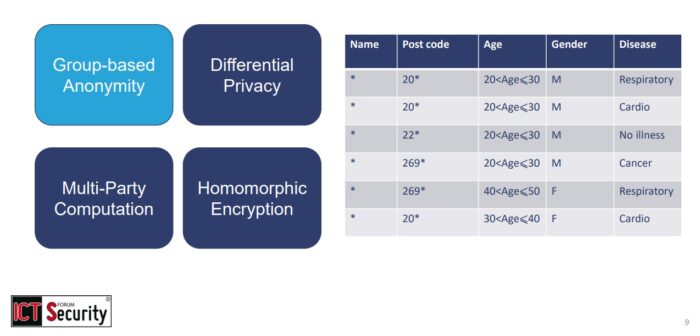
- Anonimizzazione dei dati – consiste nella rimozione di tutte le informazioni sensibili presenti in un database, come nomi o identificatori di localizzazione, per impedire che i datiencryptionencryption siano associabili a specifici individui;
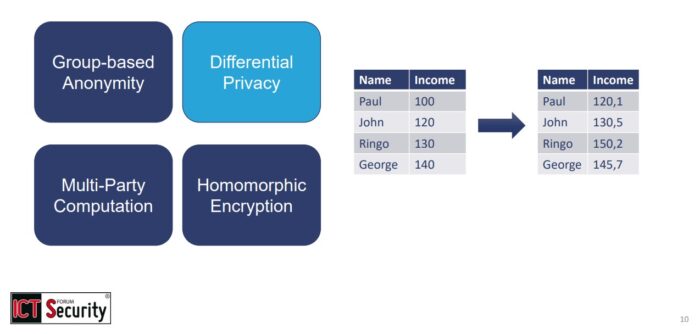
Slide dell’intervento “Machine Learning e Homomorphic Encryption: Il Futuro dell’Intelligenza Artificiale Privacy-Preserving”. Prof. Manuel Roveri al Forum ICT Security 2024 - Differential Privacy – complementare al precedente, prevede l’aggiunta di “rumore statistico” al fine di perturbare i dati per consentirne l’analisi aggregata senza divulgare informazioni dettagliate sui singoli individui, preservando così la privacy;
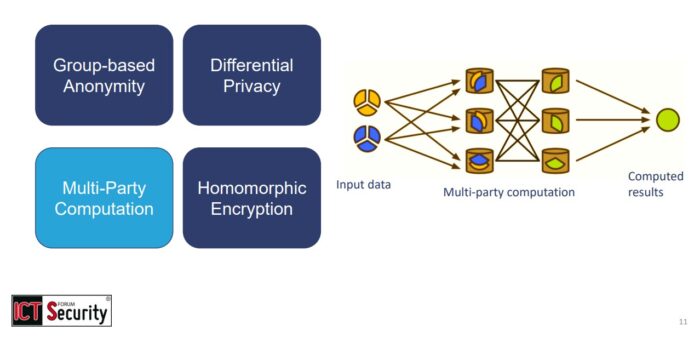
Slide dell’intervento “Machine Learning e Homomorphic Encryption: Il Futuro dell’Intelligenza Artificiale Privacy-Preserving”. Prof. Manuel Roveri al Forum ICT Security 2024 - Multi-Party Computation (MPC) – i dati vengono distribuiti “a pezzi”, in modo che nessuno abbia accesso completo alla totalità dei dati originali ma tutti possano collaborare per ottenere in sicurezza il risultato finale;
- Anonimizzazione dei dati – consiste nella rimozione di tutte le informazioni sensibili presenti in un database, come nomi o identificatori di localizzazione, per impedire che i datiencryptionencryption siano associabili a specifici individui;
- Homomorphic Encryption (HE) – consente di elaborare i dati in forma criptata ma, a differenza di altri schemi crittografici, permette di eseguire operazioni sui dati criptati fornendo un risultato che, una volta decriptato, equivale sostanzialmente a quello delle operazioni svolte sui dati in chiaro.

Slide dell’intervento “Machine Learning e Homomorphic Encryption: Il Futuro dell’Intelligenza Artificiale Privacy-Preserving”. Prof. Manuel Roveri al Forum ICT Security 2024
Tipologie di Homomorphic Encryption nell’Intelligenza Artificiale Privacy Preserving
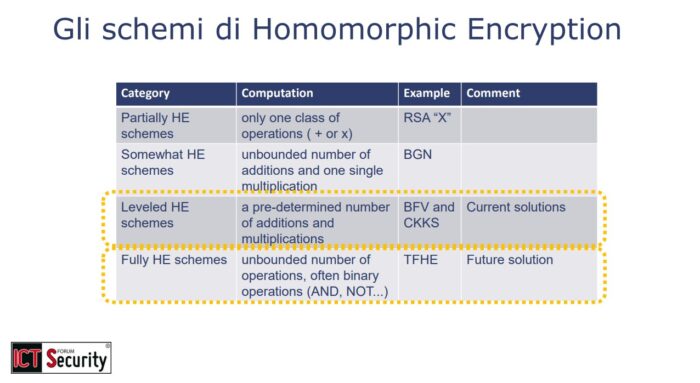
A loro volta gli schemi di homomorphic encryption si suddividono in diverse categorie, distinte in base alle loro capacità di elaborazione dei dati criptati.
- Partial Homomorphic Encryption: consente l’esecuzione di una singola operazione, come la somma o il prodotto, limitando significativamente la complessità delle operazioni.
- Somewhat Homomorphic Encryption: consente un numero illimitato di somme ma una sola moltiplicazione.
- Leveled Homomorphic Encryption: attualmente il più utilizzato, consente un numero predeterminato di somme e moltiplicazioni che lo rendono adatto a scenari di elaborazione specifici.
- Full Homomorphic Encryption (FHE): grazie al processo di bootstrapping, questo schema permette un numero illimitato di operazioni ed è considerato lo schema che in futuro potrà rivelarsi resistente agli attacchi da parte di computer quantistici.
Sfide tecniche e soluzioni per l’Intelligenza Artificiale Privacy Preserving
Come ricordato da Roveri, sebbene offrano possibilità avanzate, le tecniche di homomorphic encryption presentano anche diverse sfide.
Tra queste spiccano la necessità di trasformare le operazioni non lineari in operazioni lineari (o polinomiali) e la limitazione nella lunghezza della pipeline di elaborazione, oltre a un’elevata richiesta di memoria e potenza di calcolo. Questi sono aspetti particolarmente critici per le reti di deep learning, caratterizzate proprio da operazioni non lineari, profondità di elaborazione elevata e da un’enorme richiesta di risorse computazionali.
Simili criticità sono alla base della seconda domanda posta nel corso dell’intervento: è possibile progettare reti neurali capaci di operare su dati criptati?
Per rispondere positivamente è stato citato il caso, già oggetto di una pubblicazione scientifica, della rete di elaborazione immagini AlexNet, dove le operazioni non lineari sono state sostituite con operazioni polinomiali per poter applicare l’homomorphic encryption preservando comunque un’accuratezza comparabile all’originale. Ad esempio la versione approssimata della rete, operando su immagini criptate, raggiunge un’accuratezza del 98,1% sul dataset MNIST (rispetto al 98,7% della versione originale).
I costi in termini di occupazione di memoria sono considerevoli, passando da 7.5 MB a 780 MB; anche i tempi aumentano sensibilmente, dai pochi millisecondi della rete originale ai diversi minuti richiesti dalla rete criptata.
Tuttavia il relatore ha argomentato che tali costi – oltre a essere giustificati dalla necessità di proteggere i dati lungo l’intero processo – possono essere mitigati sfruttando macchine ad alta computazione in modalità as-a-Service, tipicamente tramite il ricorso al Cloud.
Applicazioni pratiche dell’Intelligenza Artificiale Privacy Preserving
L’applicazione delle tecniche privacy preserving, quindi, consente di sviluppare una pipeline di elaborazione dati completamente criptata, in cui i dati vengono cifrati con una chiave pubblica ed elaborati in forma criptata nel cloud.
In seguito, i risultati potranno essere decodificati esclusivamente dal proprietario dei dati.
Passando agli scenari in cui tale approccio sia già stato applicato con successo, il prof. Roveri ha presentato diversi esempi:
- Elaborazione di dati satellitari criptati – utilizzata, in collaborazione con e-GEOS, per il rilevamento e la classificazione di oggetti nell’ambito di un progetto dell’Agenzia Spaziale Europea; in questo caso la crittografia garantisce la riservatezza dei dati sensibili provenienti da satelliti di osservazione, permettendone comunque l’elaborazione.
- Elaborazione di dati genomici criptati, a cui si fa ricorso per consentire la classificazione e localizzazione primaria dei tumori senza compromettere le informazioni genomiche dei pazienti; questo approccio consente di utilizzare dati sensibili per la ricerca medica, salvaguardando la privacy dei soggetti coinvolti.
- Manutenzione predittiva su dati criptati, applicata a macchinari industriali in impianti di produzione critici; ciò consente l’elaborazione dei dati per ottimizzare la manutenzione dei sistemi, senza necessità di esporre informazioni critiche.
Prospettive future per l’Intelligenza Artificiale Privacy Preserving
Il futuro dell’Intelligenza Artificiale Privacy Preserving – che in realtà, secondo il prof. Roveri, è già presente – non si limita alla fase di inferenza, estendendosi anche alla fase di addestramento sui dati criptati.
Volendo costruire un modello di elaborazione ad hoc senza divulgare informazioni sensibili, è stato illustrato come sia possibile utilizzare un training set criptato in base al quale definire un modello che preservi la privacy durante tutto il processo di apprendimento: questa evoluzione apre la strada alla possibilità di fornire sia inferenza sia addestramento personalizzati, garantendo al contempo la riservatezza delle informazioni.
In conclusione, il relatore ha quindi ribadito come l’Intelligenza Artificiale rappresenti un’area di ricerca e sviluppo cruciale per garantire un equilibrio sostenibile tra innovazione tecnologica, tutela della privacy e sicurezza dei dati.

Manuel Roveri ha conseguito la Laurea in Ingegneria Informatica presso il Politecnico di Milano nel 2003, il Master of Science in Computer Science presso l’University of Illinois at Chicago, USA, nello stesso anno, e il Dottorato di Ricerca in Computer Engineering presso il Politecnico di Milano nel 2007. Attualmente è Professore Ordinario presso il Politecnico di Milano e Vice-Direttore del Dipartimento di Elettronica, Informazione e Bioingegneria con delega ai rapporti con le aziende. È inoltre co-fondatore di Dhiria s.r.l., uno spin-off del Politecnico di Milano che opera nell’ambito dell'Intelligenza Artificiale Privacy-Preserving. È autore di oltre 120 articoli scientifici pubblicati in riviste e conferenze internazionali. I suoi principali interessi di ricerca includono Privacy-preserving Machine e Deep Learning, Embedded and Edge Artificial Intelligence ed Adaptive Artificial Intelligence.





