
Industrial Cybersecurity – Architettura per la sicurezza
Il monitoring prevede l’acquisizione di informazioni dal/nel target system circa il suo stato e il suo funzionamento.
Tali informazioni, in formato grezzo e/o preventivamente elaborato e/o aggregato, vengono rese disponibili all’attività di detection che, in caso di errore, criticità o anomalia, coinvolge l’attività di reaction per l’attuazione delle necessarie contromisure, il tutto sotto la supervisione di personale dedicato.
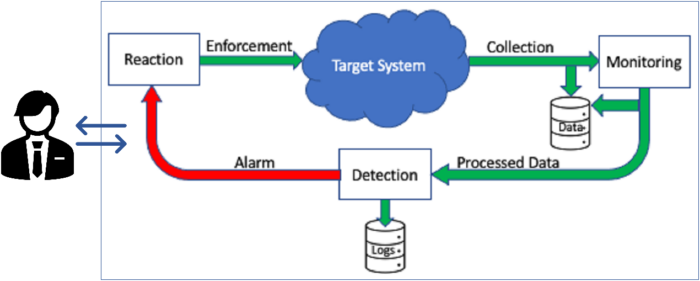
Si noti che lo schema di Figura 9 si riferisce ad attività che possono essere svolte sia totalmente dentro al sistema in esecuzione, ad esempio quanto legato ad attacchi di tipo DoS (Denial of Service) sia, parzialmente, all’esterno, come la verifica di corretta implementazione di policy di sicurezza quando (un caso tipico sono gli Industrial Control Systems) non siano disponibili meccanismi automatici (enforcement) di applicazione delle policy stesse. In tal caso, a fronte di una descrizione dettagliata del sistema, comprensiva dei meccanismi di sicurezza, fornita possibilmente in modo (semi) automatico dal monitoring, si costruisce un modello del sistema stesso, su cui si verifica, tramite opportune tecniche di analisi, che le policy di sicurezza previste per il sistema siano soddisfatte dalla sua implementazione: ad esempio verificando che chi esercita il ruolo di “operatore” su di una certa macchina non possa modificarne i “parametri di configurazione” e che a farlo possa essere soltanto il “responsabile della produzione”. Per fare ciò, occorre verificare che l’assegnazione delle credenziali agli utenti dei singoli dispositivi e la loro configurazione consenta appunto di garantire tali desiderata.
Nel caso in cui la verifica fallisca, le necessarie correzioni vengono apportate sul modello del sistema e, in caso di successiva verifica positiva, ribaltate sul sistema reale.
Per ciò che concerne le attività di monitoring, detection e reaction effettuate sul sistema reale, sono evidentemente necessari sensori o sonde di acquisizione, risorse di computazione e comunicazione e quanto altro necessario alla riconfigurazione, quindi componenti hardware e software che devono trovarsi distribuiti nel sistema stesso per assolvere alle suddette funzioni.
Questa sovrastruttura per la sicurezza dev’essere progettata indissolubilmente dal sistema nel caso di nuovi CPS, oppure aggiunta in caso di CPS esistenti, privi o non sufficientemente dotati di risorse per la sicurezza.
Esempi
Esempi di quanto sopra descritto possono provenire da recenti attività di ricerca nel settore. In particolare,
verranno introdotti:
- strumenti di analisi che operano su modelli di sistema, costruiti mediante informazioni acquisite dall’attività
di monitoring sul sistema in esecuzione; - strumenti di riconfigurazione automatica dell’infrastruttura di sicurezza a seguito di intervenute situazioni di
rischio, causate da azioni malevole o semplicemente da impreviste situazioni fisiologiche; - analisi delle prestazioni di software e dispositivi per la sicurezza, al fine di garantire che la loro introduzione
non influisca negativamente sulle prestazioni del sistema.
Analisi
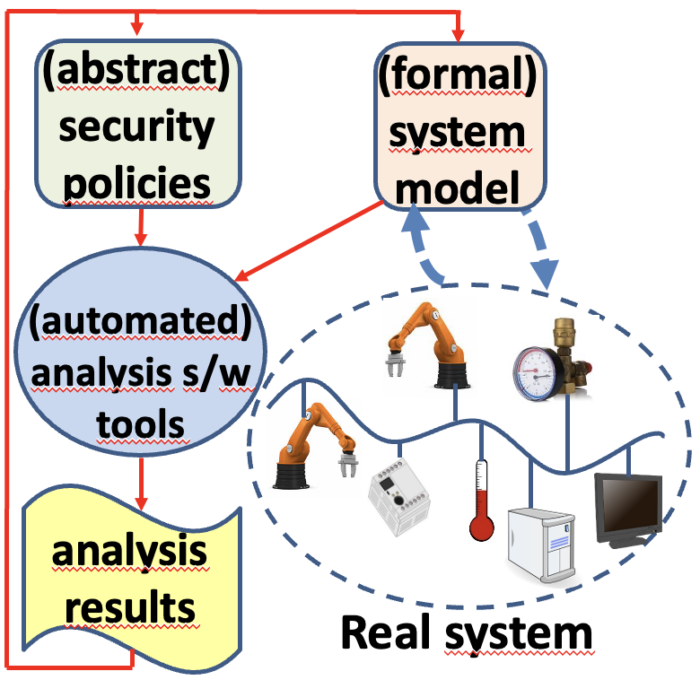
Lo schema di Figura 10 illustra il modo di operare delle metodologie di analisi di sicurezza su modelli del sistema, eventualmente acquisiti dal sistema stesso mediante il supporto del monitoring. In sostanza, l’attività di verifica svolta da un tool software determina se il modello del sistema soddisfa i requisiti di sicurezza espressi come policy. Dal risultato ottenuto si possono effettuare, sul modello e/o le policy, le opportune correzioni, da applicare infine sul sistema reale quando i risultati dell’analisi diano esito positivo.
L’esempio specifico descritto qui concerne la verifica di implementazione di policy di access control: da un lato ci sono le policy descritte mediante il formalismo RBAC e, dall’altro, il modello del sistema comprensivo di descrizione della geografia dei luoghi, locali, armadi, quadri elettrici, della configurazione di rete atta a determinare la raggiungibilità di un dispositivo da un altro, la configurazione di ciascun dispositivo con il software installato, gli account e appunto la connettività; infine gli utenti del sistema, quindi tutte le unità di personale, ciascuna con le credenziali assegnate e il ruolo (o i ruoli) di competenza. Le policy di access control di fatto definiscono direttamente chi può fare cosa e dove nel sistema: per ciascun soggetto (chi), quale azione (cosa) e su quale oggetto (dove), senza che debba essere specificato il come. A partire dalla descrizione dettagliata del sistema, si computano le medesime informazioni attraverso il come e si confrontano i due insiemi.
Eventuali discrepanze possono significare che il sistema non implementa correttamente le policy e che, quindi, occorre apportare le necessarie correzioni.
In ciò, l’analisi stessa è di aiuto: in quanto è in grado di fornire, per ogni azione da parte di un soggetto su di un certo oggetto, la sequenza di operazioni necessarie al compimento di quella che determina la discrepanza nel confronto di cui sopra (il come). In altre parole, l’analisi fornisce il controesempio. La computazione di ciò può essere decisamente onerosa, quindi particolare attenzione è stata dedicata alle ottimizzazioni, ottenute mediante la composizione degli automi a stati finiti che descrivono rispettivamente le azioni fisiche (ad es. accesso a un locale o a un cabinet attraverso una porta) e quelle cyber (ad es. accesso a server web, ssh a nodo remoto) da parte di ciascun soggetto.
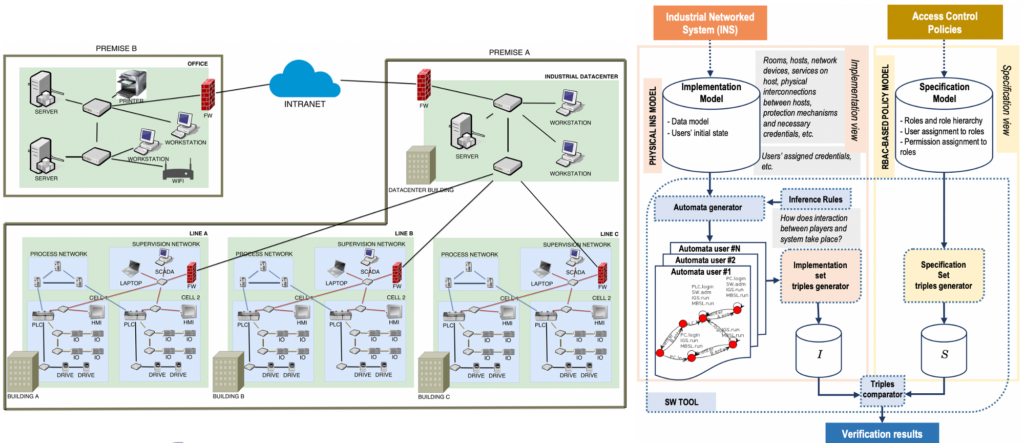
La Figura 11 fornisce un esempio specifico, costituito, sul lato sinistro, da una infrastruttura geograficamente dislocata in due siti, dove uno dei due è costituito da più edifici (capannoni) ognuno dei quali contiene più celle di lavoro, ciascuna con le proprie connessioni all’interno e verso l’esterno. I collegamenti di rete tra edifici e verso l’esterno sono protetti da firewall. Per tutti i dispositivi e i locali descritti si conoscono le azioni che è possibile effettuare su ciascuno, nonché le eventuali credenziali necessarie e le configurazioni (server software installati, ad esempio). Non rappresentati in figura ci sono poi i soggetti che popolano la struttura, ad esempio i manutentori, l’ingegnere di produzione, gli operatori di linea ecc., ciascuno con le credenziali che gli sono state fornite.
La parte destra della Figura 11 descrive come vengono elaborate la suddetta descrizione – chiamata Implementation Model – e l’insieme delle policy di access control, chiamato Specification Model: da ciascuno si determinano i due rispettivi set I e S di triple chi agisce dove (soggetto, azione e oggetto) che vengono confrontati. Alla luce del risultato del confronto vengono attuate le eventuali correzioni, modificando opportunamente il modello del sistema o le policy. Si noti che in questo modo di procedere si riconoscono i passi dell’ISM descritti in Figura 8: Identification of Assets in the Broader Sense è il sistema con la sua geografia, geometria e dispositivi che lo occupano e relative interconnessioni, Definition of Security Policies and Threats sono le policy di access control, mentre il Risk Assessment non compare in maniera esplicita ma il suo effetto è la determinazione della configurazione del sistema, anch’essa parte della sua descrizione per ciò che concerne i meccanismi di sicurezza.
La fase di Validation è qui costituita dall’analisi vera e propria.
Riconfigurazione Dinamica
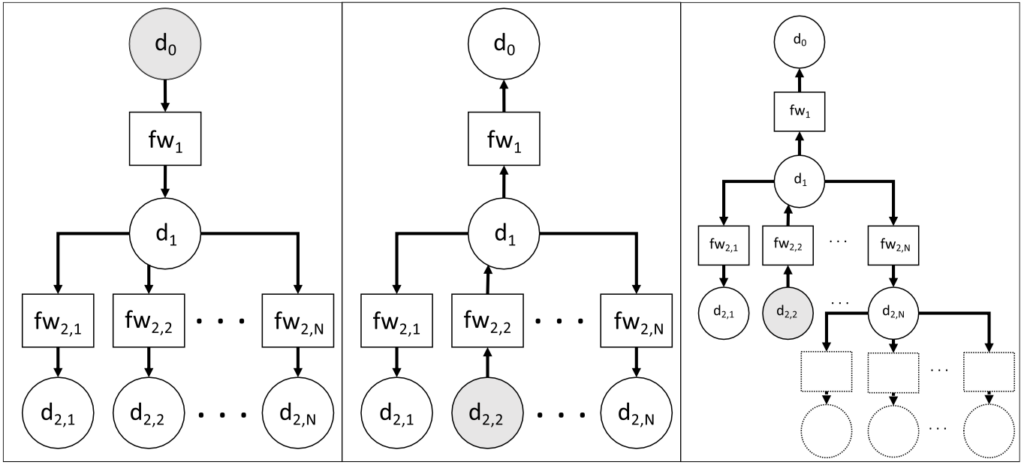
La ridistribuzione dinamica delle regole di filtraggio, tra firewall che risiedono nella stessa rete, è una soluzione tecnica in grado di far fronte a variazioni temporanee del carico di traffico elaborato dai firewall stessi.
Nelle reti che includono più firewall in cascata, questi possono essere sfruttati per consentire il trasferimento di un insieme di regole da un firewall ai suoi vicini “a valle”, quando i cambiamenti nel profilo del traffico di input lo suggeriscono. Il meccanismo su cui si basa questa tecnica è la riduzione del numero medio di regole controllate per pacchetto, al fine di aumentare la velocità di elaborazione dei pacchetti. Il modello di rete tiene conto sia della topologia del sistema che delle caratteristiche del firewall. Un opportuno algoritmo di trasformazione sposta le regole tra i firewall in cascata, consentendo miglioramenti tangibili delle prestazioni in termini di velocità di elaborazione dei pacchetti per un dato profilo di traffico e garantendo l’integrità di sicurezza della rete. Lo scotto da pagare è un maggior consumo di banda, dato che anche ai pacchetti che verranno scartati è consentito effettuare un percorso più lungo nella rete del sistema. Per questa ragione, tale metodologia è utile durante le fasi di aumento del traffico, ma conviene tornare alla configurazione iniziale nel momento in cui la situazione di sofferenza abbia termine. La Figura 12 illustra parte di quanto descritto: data la topologia della rete, che può essere fisica o virtuale, con i dispositivi di rete fisici o virtualizzati, eventualmente basati su SDN (Software Defined Networks) e NFV (Network Function Virtualization), il flusso del traffico critico, indicato dal verso delle frecce che descrivono i collegamenti di rete, muove dal nodo sorgente, in grigio, verso le destinazioni. Ad esempio, fw1 è il firewall sovraccarico nello schema di sinistra della figura, mentre lo stesso ruolo è recitato da fw2,2 nello schema centrale. Lo schema di destra illustra invece la modularità e la scalabilità dell’approccio: se, per motivi diversi, una parte di rete non può o non deve essere considerata in dettaglio, può venire assimilata ad un singolo nodo a cui vengono associati tutti gli indirizzi della sottorete che rappresenta.
Riferendosi alla Figura 9, la situazione di criticità deve venire identificata dall’attività di detection che attinge dal monitoring, che quindi deve poter acquisire in tempo reale informazioni circa le prestazioni dei singoli firewall: ad esempio dai firewall stessi se possono rendere disponibili informazioni sul loro stato, quali il numero di pacchetti in coda, oppure da misure indirette quali la latenza dei pacchetti, cioè quanto tempo impiegano ad attraversare ciascun firewall. In quest’ultimo caso occorre disporre di un sofisticato sistema di acquisizione e misurazione, basato ad esempio su TAP (Test Access Point). Lo stesso monitoring può essere di aiuto nel determinare la topologia della rete, necessaria all’attività di reaction per il calcolo della nuova configurazione a partire dalla configurazione corrente dei firewall, da iniettare poi nei firewall coinvolti dalla trasformazione.
Tutto ciò per dire che in questo caso, come in moltissimi altri, la gestione efficace – e quindi ampiamente automatizzata – della sicurezza richiede una sovrastruttura non banale, la cui attività non deve inficiare le prestazioni richieste al CPS e che deve a sua volta essere sicura.
Prestazioni
La disponibilità di studi prestazionali e modelli semplici per firewall in grado di gestire protocolli di comunicazione a livello di applicazione industriale, come Modbus/TCP, è cruciale quando l’impatto di questi dispositivi deve essere stimato, anche approssimativamente, prima della loro effettiva messa in funzione nel sistema destinazione. Sfortunatamente, la maggior parte dei produttori non fornisce questo tipo di informazioni per i prodotti disponibili in commercio. Pertanto, una soluzione praticabile è lo sviluppo e la convalida sperimentale di modelli semplici che possono essere utilizzati dai progettisti per prevedere quelle caratteristiche del firewall non esplicitamente correlate alle loro capacità di sicurezza. Ad esempio, la latenza introdotta sull’inoltro dei messaggi è un aspetto di notevole interesse in molti sistemi di controllo industriale, dove ritardi e oscillazioni nei tempi di gestione dei pacchetti possono avere un forte impatto sull’efficacia del controllo e dell’automazione. È pertanto necessario disporre di modelli prestazionali per dispositivi commerciali per la sicurezza nei CPS. In particolare, qui si riporta brevemente l’esperienza che ha portato a caratterizzare un dispositivo commerciale in grado di eseguire filtraggio avanzato a livello di applicazione del traffico Modbus/TCP. Una serie di esperimenti progettati ad hoc, eseguiti per mezzo di un testbed di laboratorio appositamente sviluppato, ha consentito sia lo sviluppo che la validazione del modello, confermando una buona corrispondenza delle prestazioni stimate con il comportamento effettivo del dispositivo.

La Figura 13 illustra lo schema concettuale del sistema di misura: a sinistra senza dispositivo, per la caratterizzazione del sistema stesso, a destra con il dispositivo da caratterizzare. In sostanza, il nodo TG genera e spedisce pacchetti con cadenza costante programmabile e lunghezza costante programmabile, il TAP duplica il messaggio e il ricevitore R riceve le due istanze sulle porte r e s, salvando, per ciascun pacchetto ricevuto su ciascuna porta, il tempo di arrivo. Nel caso dello schema di sinistra i due tempi, che dovrebbero teoricamente coincidere, differiscono di pochi microsecondi per il fatto che vengono gestiti in sequenza dalla routine di interrupt di R, che impiega appunto qualche microsecondo. Questa differenza non inficia le misure effettuate con l’inserimento del dispositivo da caratterizzare, nello schema di destra, perché quest’ultimo introduce una latenza sempre superiore ai 100 microsecondi, rendendo marginale, quindi trascurabile, la latenza introdotta dal sistema di misura: infatti la differenza tra i tempi di arrivo a R delle due istanze di ciascun pacchetto trasmesso da TG è, al netto della marginale latenza del sistema di misura, la latenza che il dispositivo introduce.
Il dispositivo è in grado di filtrare traffico TCP e UDP standard e traffico Modbus/TCP, cioè pacchetti TCP il cui payload è costituito da un pacchetto Modbus. Mentre il traffico “standard” viene filtrato in base al contenuto dell’header del pacchetto, quindi il test rispetto alle regole di filtraggio è veloce, il traffico Modbus/TCP per essere filtrato richiede l’analisi del payload del pacchetto, quindi è certamente più oneroso da un punto di vista computazionale. Ciò comporta un rischio: da un lato si vuole filtrare traffico potenzialmente affetto da vincoli temporali anche stringenti e, dall’altro, questo filtraggio è computazionalmente oneroso, quindi rischia di introdurre latenze incompatibili con gli eventuali vincoli temporali che il controllo impone alla comunicazione.
Questo giustifica un’indagine approfondita per determinare l’esatto comportamento del dispositivo e la latenza introdotta dall’attività di filtraggio. Dai dati forniti dal produttore, non è possibile inferire alcunché circa la struttura funzionale del dispositivo, né il ritardo introdotto dal filtraggio; ma grazie a una serie di campagne di misura, dapprima per il solo traffico “standard” e poi per il traffico Modbus/TCP, è stato possibile determinare lo schema funzionale del firewall con estrema precisione, riuscendo anche a determinare i tempi di attraversamento di ciascun blocco da parte del pacchetto sotto esame, come illustrato in Figura 14.

In particolare, è risultato che il dispositivo è di fatto costituito da due firewall in sequenza, Q1 e Q2, dove Q1 è un tradizionale firewall IP mentre il secondo riceve dal primo solo i pacchetti Modbus/TCP, non gestiti da Q1. In base a ciò, risulta che il traffico “standard” ha la priorità sul traffico Modbus/TCP; inoltre il filtraggio dei pacchetti ModbusTCP, accumulati eventualmente nel buffer B2, avviene soltanto quando Q1 è inattivo, riducendo ulteriormente la priorità del filtraggio di tale traffico.
Le misure effettuate con data rate 100 Mb/s hanno consentito di determinare la lunghezza dei due buffer B1 e B2: 256 elementi ciascuno, e sono rispettivamente circa 31.95 , 138.87 e 0.745 microsecondi e rappresentano il tempo medio di attesa del pacchetto prima di essere accodato nel buffer B1, il tempo medio di attesa prima che il pacchetto, estratto da B1, venga valutato rispetto alle regole di Q1 e il tempo medio di valutazione del pacchetto rispetto ad una singola regola: quindi se la regola soddisfatta è in posizione R, il tempo di valutazione è . Circa Q2, invece, è in media 99.27 microsecondi, mentre il tempo di valutazione del pacchetto rispetto alle regole Modbus/TCP è in media 282.75 microsecondi e non dipende dalla posizione della regola soddisfatta.
Tale modello è stato poi validato mediante ulteriori campagne di misura dove, date le caratteristiche del traffico iniettato, la latenza prevista, determinata utilizzando il modello, è risultata coincidente con il valore misurato.
Il risultato, in sintesi, è che il dispositivo ha una latenza compresa tra 100 e 600 microsecondi (a seconda del tipo di pacchetto e della posizione della regola soddisfatta) e che il firewall non è in grado di gestire flussi superiori ai 2000 pacchetti per secondo.
L’importanza di questa esperienza non è tanto nei numeri che sono stati determinati, quanto nel fatto che nessuno di questi è reso noto dal produttore, rendendo di fatto impossibile stabilire a priori se il dispositivo sia idoneo e compatibile con le caratteristiche del traffico e del sistema che dovrebbe impegnarlo. Ciò deve quindi portare a una grande attenzione e prudenza nella scelta di dispositivi di sicurezza per i CPS: senza un’indicazione delle performance, infatti, non è possibile stabilire la compatibilità del dispositivo rispetto alle necessità del traffico da filtrare o da gestire.
Conclusioni
Da una prospettiva storica, i requisiti di sicurezza dei CPS sono stati tradizionalmente specificati da organizzazioni attive in una serie di domini di infrastrutture critiche, tra cui, ad esempio:
- distribuzione di acqua e gas;
- trasmissione e distribuzione di energia elettrica;
- produzione di gas e petrolio;
- produzione e distribuzione alimentare;
- sistemi di trasporto.
In tutti questi ambiti, la security è sempre stata tenuta in debita considerazione: quindi si sono inizialmente sviluppate linee guida e raccomandazioni specifiche, oggi certamente obsolete ma comunque importanti nell’evoluzione darwiniana delle linee guida per la security dei CPS.
Nel tempo, infatti, i requisiti comuni sono stati individuati, fusi e amalgamati in diversi documenti da vari organismi di normazione internazionali e nazionali. Oggi l’Information Security Management (ISM) è universalmente considerato come un processo, chiamato anche Information Security Program (ISP) dal NIST, che ha recentemente introdotto un importante aggiornamento alla sua linea guida. Questo documento, nella sua ultima versione, sebbene ancora in forma di draft, è considerato tra i migliori e più completi punti di partenza per approfondire le tematiche della security dei CPS a 360°.
Indipendentemente dalla loro diversa struttura e grado di generalità, tutti i principali sforzi di normazione concordano, in pratica, sullo stesso concetto di base.
Ovvero:
i rischi per la sicurezza devono essere minimizzati mediante opportuni controlli che affrontino le vulnerabilità sfruttabili da possibili minacce, il cui obiettivo è l’abuso e/o il danneggiamento dei beni.
Concetto che, al termine del presente documento, dovrebbe risultare del tutto chiaro e condiviso, alla luce dell’aumentata sensibilità e consapevolezza che si spera siano progressivamente maturate con la lettura del medesimo.

Questo articolo è stato estratto dal white paper “Industrial Cybersecurity” disponibile in maniera gratuita al seguente link: https://www.ictsecuritymagazine.com/pubblicazioni/industrial-cybersecurity/
Articolo a cura di Luca Durante

Luca Durante è Primo Ricercatore presso l’Istituto di Elettronica e Ingegneria dell’Informazione e delle Telecomunicazioni del Consiglio Nazionale delle Ricerche (CNR-IEIIT) di Torino.
Nel 1996 ha conseguito il Dottorato di Ricerca in Ingegneria Informatica presso il Politecnico di Torino, è autore di oltre 70 articoli per riviste e conferenze internazionali, ed è stato ed è tuttora Responsabile Scientifico per il CNR in Progetti Europei e in contratti di ricerca con aziende.
È stato inoltre general co-chair, program co-chair e membro del comitato di
programma di conferenze internazionali, associate editor di IEEE Transactions on Industrial Informaatics e revisore per riviste internazionali.
Gli interessi di ricerca vertono principalmente sulle tematiche di sicurezza
informatica, attualmente declinati sulle policy di sicurezza per il controllo di accessi e la sicurezza dei sistemi cyber-fisici.





