Il problema del BIAS nei dataset e della XAI (eXplainable Artificial Intelligence)
L’Intelligenza Artificiale (IA) integra Machine Learning e Deep Learning per elaborare dati e generare previsioni. Esaminiamo i concetti fondamentali dell’IA, le sue applicazioni e le sfide etiche come privacy e BIAS, andando alla scoperta di soluzioni come XAI per contrastare pregiudizi negli algoritmi. Analizziamo poi l’impatto dell’IA sulla società, evidenziando l’importanza di un approccio equilibrato nello sviluppo e nell’implementazione di sistemi IA.
Machine Learning e Deep Learning: i sottoinsiemi dell’IA
L’Intelligenza Artificiale (IA) è un concetto che abbraccia varie branche del sapere umano, dalla filosofia alla matematica, statistica, informatica ed anche la sociologia e psicologia.
L’IA è un macro insieme che contiene due sottoinsiemi, il Machine Learning ed il Deep Learning, essi sono due modalità d’apprendimento ed elaborazione dei dati in ingresso per ottenere delle previsioni in uscita.
L’intelligenza artificiale o IA è un campo di sviluppo dell’informatica, che tende ad emulare l’intelligenza umana e riprodurre gli schemi di ragionamento tramite algoritmi. Gli organismi biologici, come gli esseri umani, ma anche gli animali, imparano dall’esperienza e dall’osservazione del mondo, su questo concetto si sviluppano gli algoritmi che dovrebbero imparare analizzando i dati che ricevono in input.
L’IA comprende la definizione di intelligenza, cerca di modellizzare in modo algoritmico i processi d’apprendimento e di evoluzione per emulare l’intelligenza umana su delle macchine, ma il concetto di IA “general purpose”, detta anche IA forte o generale; quindi, quella che viene rappresentata nei film di fantascienza, è ancora un obbiettivo irraggiungibile.
Lo stato attuale dell’arte è rappresentato dall’IA ristretta, ossia dedicata allo svolgimento di specifici compiti, come la guida autonoma dei veicoli, la classificazione per immagini, la previsione di alcuni valori numerici, e.g. prezzi, azioni di borsa, la classificazione dei testi, etc…
Il Machine Learning (ML) è un sottoinsieme dell’IA, che si sviluppa tramite algoritmi che elaborano dati preordinati e può essere di due tipologie:
Supervisionato – le variabili di uscita, gli output, sono mappati con una label (etichetta), quindi nel dataset (l’insieme dei dati), vi sono l’input e gli output attesi.
Esempio:
| Altezza | Peso | Etichetta |
| 25 | 3 | Gatto |
| 56 | 14 | Cane |
Non Supervisionato – nel dataset ci sono solo variabili di input senza alcun output atteso; quindi, la rete deve imparare a trovare degli schemi e classificare o predire.
Con Rinforzo – è un apprendimento in ambiente dinamico, lo scopo è raggiungere un target e per farlo ci saranno delle ricompense o punizioni (numeriche, vedi Q-Learning).
Classificazione – agli input vanno assegnate delle classi definite nel dataset, quindi l’algoritmo riesce a classificare un certo input (feature) ad un certa label (variabile Y) tipico dell’apprendimento supervisionato
Regressione Lineare – le label non sono discrete ma valori continui, quindi l’algoritmo cercherà di predire la label relativa a certi input d’ingresso (es. valore azioni in borsa, ecc.) – sempre supervisionato
Clustering – una classificazione per gruppi non noti a priori, si cercano schemi che possano creare dei cluster omogenei – non supervisionato
Il Deep Learning (DL) è una forma d’apprendimento nel quale le caratteristiche sono estratte direttamente dall’input e non sono fornite ab origine in forma numerica, ad esempio si forniscono migliaia di fotografie di gatti e di cani e l’algoritmo cercherà di estrarre da esse delle caratteristiche che serviranno a determinare se in un’immagine vi sia raffigurato un cane o un gatto.
La base del Machine Learning e Deep Learning e i problemi tecnici
Il ML ed il DL funzionano tramite la creazione di reti composte da neuroni artificiali, che sono algoritmi che simulano il funzionamento di un neurone biologico, tramite complesse elaborazioni matematiche.
L’algoritmo deve essere addestrato prima di poter esser considerato affidabile per le previsioni che dovrà effettuare.
La fase d’addestramento consiste nel valutare quanto un input sconosciuto si avvicini all’output atteso, calcolando la minimizzazione dell’errore (funzione di costo); quindi, se si sa che ad un dato X deve corrispondere un certo Y, l’algoritmo deve calcolare dei “pesi”, valori numerici casuali, tali per cui dopo delle elaborazioni matematiche sarà sempre più preciso al fine di rendere la funzione di costo più piccola e quindi far coincidere il valore previsto con quello di output.
“L’intelligenza non è la conoscenza ma è la capacità d’immaginazione” – A. Einstein, da questa citazione si può partire per descrivere sinteticamente i problemi di “underfitting” ed “overfitting”, ossia gli algoritmi non devono essere troppo precisi ed accurati nella previsione (overfitting) e nemmeno troppo generici (underfitting).
L’overfitting, infatti, crea una scarsa capacità dell’algoritmo di generalizzare; pertanto, non saprebbe riconoscere qualcosa che si discosta leggermente da quello che ha imparato, ad esempio se sa riconoscere perfettamente le forme quadrato e cerchio, nel momento in cui incontra un ovale non saprebbe come classificarlo.
L’underfitting ha il problema inverso, ossia l’algoritmo non sa riconoscere nemmeno tutto quello che ha imparato, creando molti errori.
I problemi sociali dell’IA: bolle di filtraggio e privacy
Nello sviluppo degli algoritmi di IA, si sono riscontrati dei problemi che sono più “sociali” che tecnici, ossia che colpiscono la sfera delle decisioni umane.
Filter Bubbles – Sappiamo che servizi come Netflix, Spotify, Amazon, Facebook e tanti altri spesso ci suggeriscono qualcosa da vedere, ascoltare o comprare, basandosi sulle nostre scelte fatte nel passato, ma anche sulle scelte di altri utenti che hanno avuto gusti simili ai nostri.
Quindi se ad esempio si è scelto di guardare un film di fantascienza, il servizio di streaming, proporrà altri film di fantascienza, ma anche film di altri generi, che magari sono stati scelti da altri utenti che avevano visionato lo stesso film.
Questo meccanismo si chiama “filter bubbles”, ossia bolle di filtraggio, poiché si rimane dentro un sistema di raccomandazione filtrato attraverso delle scelte più o meno omogenee. Ci sono tanti vantaggi in questo sistema, come la velocità, il servizio di avere qualcuno che “ti conosce” o presume di conoscerti e quindi ti serve bene, ma ci sono anche gli svantaggi dati dal “confinamento” dell’informazione; quindi, si riceve sempre una stessa linea di pensiero, cosa meno grave per i film o la musica, ma potrebbe esser più grave per l’informazione politica o generale.
Privacy – Il problema più grande del legame Privacy e IA è dato dal fatto che un’IA può dedurre altri dati personali partendo da alcuni dati per i quali abbiamo dato il consenso, può trattarli per altri scopi, non si sa chi li detiene, può creare delle filter bubbles, non sarebbe punibile in caso di trasgressione.
Il BIAS nei dataset: cause, esempi e contromisure
Il bias cognitivo (pronuncia inglese [ˈbaɪəs]) o distorsione cognitiva è un pattern sistematico di deviazione dalla norma o dalla razionalità nel giudizio. In psicologia indica una tendenza a creare la propria realtà soggettiva, non necessariamente corrispondente all’evidenza, sviluppata sulla base dell’interpretazione delle informazioni in possesso, anche se non logicamente o semanticamente connesse tra loro, che porta dunque a un errore di valutazione o a mancanza di oggettività di giudizio – Fonte: https://it.wikipedia.org/wiki/Bias_cognitivo
L’IA è sviluppata da esseri umani, che sono pervasi di cultura e percezione della realtà soggettiva e/o condizionata dall’ambiente in cui vivono, quindi si rischia di addestrare un algoritmo su degli insiemi di dati “inquinati” da pregiudizi (bias), che possono influenzare l’output.
Esempi noti di IA afflitte da BIAS
- Compas– prevedeva una recidiva criminale maggiore nell’etnia afro-americana.
- Dataset sbilanciato verso una certa etnia è meno preciso verso
- BOT che impara dai dati raccolti in rete (es. TAY bot di Microsoft su twitter), che se sono per la maggioranza scritti da una certa parte di persone, rischia di essere prevalentemente di quella parte e rispondere come
- Esempio: se un ML si addestra sui dati raccolti sul tema «cura del cancro» e le sue fonti provengono per lo più dai social, potrebbe diventare un’AI che consiglia terapie farlocche e fake
- Il caso “Gender Shades” dove si dimostra come il riconoscimento facciale di alcuni grandi software di IA sbagliava di molto sull’etnia di
- Amazon che preferiva il genere maschile al femminile nell’assunzione.
Contromisure ai BIAS nell’IA
- È necessario un approccio multidisciplinare nella creazione degli algoritmi e dataset;
- Interessante framework IBM: AI Fairness 360
- Inclusione, trasparenza, privacy, responsabilità, imparzialità: Call for AI Ethics
- Approfondimento sul caso COMPAS
- Bisogna cercare di evitare di inserire/valutare in base ai «protected attributes» ossia gli attributi riguardanti etnia, genere, orientamento, . Laddove non servono, per esempio il sesso nel recruitment.
- L’overfitting può causare BIAS
- De-Biasing by IBM
XAI: l’intelligenza artificiale “spiegabile” e il suo ruolo nel contrastare il BIAS
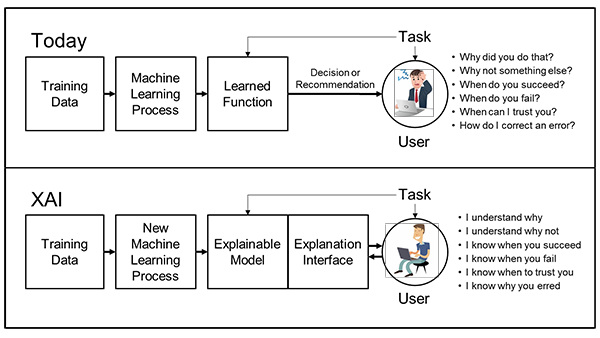
Una delle contromisure ed anche un sistema per capire meglio l’output di un algoritmo di IA è quello della XAI (eXplainable Artificial Intelligence), ossia l’intelligenza artificiale spiegabile.
Gli algoritmi sono sostanzialmente delle black box, delle scatole nere nelle quali entrano i dati di input, che vengono elaborati per generare degli output, il motivo per cui sia stata generata una risposta rispetto ad un’altra non è facilmente comprensibile.
Per questo motivo, servono sistemi che permettano all’essere umano di comprendere quali variabili hanno condizionato la previsione in uscita, al fine di capire quanto pesano nella decisione algoritmica e se sono importanti per essa o sono frutto di pregiudizio.
Lo scrivente ha creato un dataset volutamente affetto da pregiudizio razziale, con parametri di discriminazione, come la razza e il numero di crimini commessi in passato dal soggetto, immaginando due etnie, i Terrestri ed i Marziani.
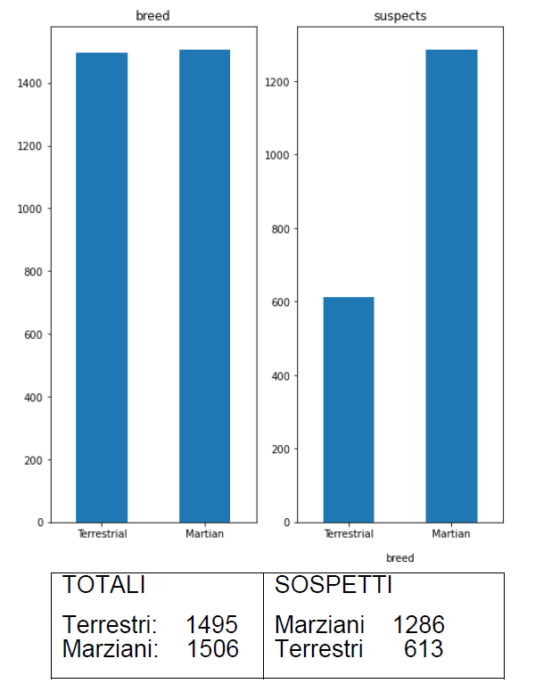
Il dataset è sbilanciato verso i “Marziani”, che hanno più possibilità di essere classificati come ‘sospetto‘, se il soggetto è Terrestre, casualmente sarà sospetto o no.
Il set di dati è influenzato dagli attributi di età e razza
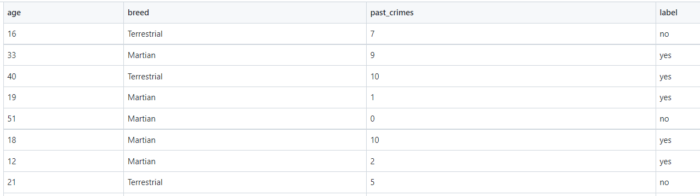
Il dataset è così composto:
Fornendo in input un soggetto di 61 anni, terrestre e con 3 crimini passati si ottiene l’output:
[61 1 3]
Accuracy Train: 81.29 % Accuracy Test: 65.37 %
CHECK A TERRESTRIAL
Predicted target name: [‘no’]
[‘age’, ‘breed’, ‘past_crimes’, ‘suspect’]
[61, 1, 3] [‘no’]

Il TERRESTRE non è considerato sospetto e l’analisi tramite LIME, per ottenere una spiegazione della decisione, mette in evidenza che la variabile che ha condizionato l’output è l’etnia.
Si fornisce un soggetto di 61 anni, marziano e con 3 crimini passati si ottiene l’output:
[61 0 3]
Accuracy Train: 81.29 % Accuracy Test: 65.37 %
CHECK A MARTIAN
Predicted target name: [‘yes’]
[‘age’, ‘breed’, ‘past_crimes’, ‘suspect’]
[61, 0, 3] [‘yes’]

Il MARZIANO è considerato sospetto e l’analisi tramite LIME, per ottenere una spiegazione della decisione, mette in evidenza che le variabili che hanno condizionato l’output sono l’etnia, età e crimini passati.
Infine, si fornisce in input solo un soggetto di 61 anni con 3 crimini in passato e nessuna informazione sull’etnia.
[61 3]
Accuracy Train: 81.29 % Accuracy Test: 65.37 %
CHECK WITH NO BREED
Predicted target name: [‘no’]
[‘age’, ‘breed’, ‘past_crimes’, ‘suspect’]
[61, 3] [‘no’]
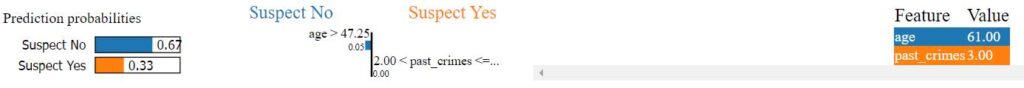
Eliminando l’etnia si ottiene che il soggetto non è sospetto, basandosi solo sulle variabili dei crimini commessi in passato e sull’età.
Da questa simulazione un analista può capire quali sono le variabili che condizionano l’output ed intervenire sull’algoritmo o sul dataset, eliminando eventualmente i parametri che inseriscono un pregiudizio, diversamente si sarebbe ottenuto il risultato senza comprendere cosa lo avesse influenzato.
Riflessioni finali sul BIAS nell’IA e il suo impatto nella società
Il BIAS nell’Intelligenza Artificiale è ereditato dai pregiudizi umani, che sono insiti in ogni cultura e sono diversi per ogni cultura, questo scenario apre svariate riflessioni sull’idea che l’IA debba essere uno specchio del modo di ragionare umano o se il pregiudizio è utile o meno.
Nel campo della Giustizia diventa veramente complesso pensare ad una sentenza emessa da un’IA, dovendo analizzare vari fattori che spesso possono essere afflitti da preconcetti o da statistiche non perfettamente “pure”.
La Giustizia, specialmente del “civil law” non è una semplice concatenazione di “IF THEN” ma comprende anche tante interpretazioni umane che possono differire per ogni Giudice, pertanto forse è ancora prematuro pensare ad un IA per tali applicazioni, ma il futuro è sempre più vicino.
Articolo a cura di Giovanni Bassetti

Dott. Giovanni Bassetti, laureato in Scienze dell’Informazione, iscritto all’Albo dei Consulenti Tecnici presso il Tribunale Civile di Bari al n. 17, Project Manager della Live Distro internazionale CAINE per le indagini informatiche forensi, nonché fondatore della comunità italiana online dedicata alle investigazioni digitali (Computer Forensics Italy), autore di numerosi articoli pubblicati su riviste del settore nazionali ed internazionali. È stato consulente per alcuni procedimenti penali di rilevanza nazionale, è autore di un testo sulla computer forensics ed è segretario e membro fondatore di ONIF (Osservatorio Nazionale Informatica Forense).
Inoltre, ha partecipato come relatore e docente a numerosi convegni e corsi nazionali ed internazionali dedicati all’informatica forense ed intelligenza artificiale.