Artificial intelligence (AI) e Sanità
La Commissione Europea ha di recente ricordato come “Artificial intelligence (AI) is not science fiction; it is already part of our everyday lives, from using a virtual personal assistant to organise our day, to having our phones suggest songs we might like”[1].
In tal senso, a fronte di una proliferazione spesso abusata del termine “intelligenza artificiale”, bisogna ricordare con sempre maggiore enfasi che la stessa necessita di un approccio cosciente e (in)formato per poter essere adeguatamente governata, anche a protezione dei diritti e delle libertà degli interessati.
L’applicazione di un agente/prodotto/sistema di AI richiede, anzitutto, che siano rispettati i seguenti principi:
- Dignità e supervisione umana;
- Robustezza e sicurezza;
- Privacy e governance dei dati;
- Trasparenza;
- Diversità, non discriminazione ed equità;
- Benessere sociale e ambientale;
- Accountability.
Ma oltre ai principi è necessario considerare gli impatti che produce e, ancor di più, a quali rischi si va incontro facendone uso, ossia:
- Generalità
- Correttezza
- Sicurezza
- Safety
- Tutela della privacy
- Robustezza
- Trasparenza e spiegabilità.
Nello specifico ambito sanitario, in tal senso possono essere di evidente aiuto – supportandoci nella comprensione di quanto sopra citato – alcuni documenti, quali ad esempio il report[2] dedicato all’AI in ambito sanitario emesso nel 2023 dalla World Health Organization, dove si precisa che:
“Questo documento fornisce una panoramica delle considerazioni normative sull’IA per la salute coprendo argomenti chiave quali: documentazione e trasparenza, gestione del rischio e ciclo di vita dello sviluppo dei sistemi di IA l’uso previsto e la convalida analitica e clinica, la qualità dei dati, la privacy e la protezione dei dati l’impegno e la collaborazione.
Questo documento vuole essere un elenco delle principali considerazioni normative e una risorsa che può essere considerata da tutti i portatori di interessi pertinenti negli ecosistemi dei dispositivi medici, compresi gli sviluppatori che stanno esplorando e sviluppando sistemi di IA, le autorità di regolamentazione che potrebbero essere in procinto di gestire e facilitare i sistemi di IA, i fabbricanti che progettano e sviluppano dispositivi medici integrati nell’IA, i professionisti che distribuiscono e utilizzano tali dispositivi medici e sistemi di IA e altri che lavorano in questi settori“.
In particolare, il documento, suddiviso in 6 aree, descrive gli impatti e i rischi ai quali è soggetta l’applicazione con riferimento alla salute delle persone.

Queste aree descrivono, in maniera dettagliata, le problematiche che si possono incontrare, e così:
- Documentazione e trasparenza: pre-specificare e documentare lo scopo medico previsto nel processo di sviluppo, quali la selezione e l’uso di set di dati, norme di riferimento, parametri, metriche, deviazioni dai piani originali e aggiornamenti durante le fasi di sviluppo, dovrebbero essere in modo da consentire di tracciare le fasi di sviluppo, se del caso. Un approccio basato sul rischio dovrebbe essere preso in considerazione anche per il livello di documentazione e di conservazione dei dati sviluppo e validazione di sistemi di IA.
- Approcci al ciclo di vita della gestione del rischio e allo sviluppo di sistemi di IA: un ciclo di vita totale del prodotto dovrebbe essere preso in considerazione in tutte le fasi del ciclo di vita di un sistema di IA, vale a dire: gestione dello sviluppo, sorveglianza post-commercializzazione e gestione del cambiamento. Inoltre, è prendere in considerazione un approccio di gestione del rischio che affronti i rischi associati ai sistemi di IA, come le minacce e le vulnerabilità alla cibersicurezza, l’underfitting, i pregiudizi algoritmici, ecc.
- Destinazione d’uso e convalida analitica e clinica: Inizialmente, fornire una documentazione trasparente dell’uso previsto del sistema di IA. Dettagli della composizione del set di dati di training alla base di un sistema di IA, comprese le dimensioni, l’impostazione e la popolazione, i dati di input e output e composizione demografica – dovrebbero essere documentati in modo trasparente e forniti agli utenti.
Inoltre è fondamentale prendere in considerazione la possibilità di dimostrare le prestazioni al di là dei dati di addestramento e test attraverso validazione analitica in un set di dati indipendente. Questo set di dati di convalida esterno deve essere rappresentativo della popolazione e dell’ambiente in cui si intende utilizzare il sistema di IA e dovrebbe essere indipendente del set di dati utilizzato per lo sviluppo del modello di IA durante l’addestramento e il test. Documentazione trasparente dell’insieme di dati esterno e delle metriche di prestazione. È importante prendere anche in considerazione una serie graduata di requisiti per la convalida clinica in base al rischio. Gli studi clinici randomizzati sono “gold standard” per la valutazione delle prestazioni cliniche comparative e potrebbe essere strumenti a più alto rischio o in cui è richiesto il più elevato livello di evidenza. In altre situazioni, le prospettive.
La convalida può essere presa in considerazione in una prova di distribuzione e implementazione nel mondo reale che include un comparatore pertinente che utilizza gruppi accettati. Infine, un periodo di post-dispiegamento più intenso dovrebbe essere preso in considerazione attraverso la sorveglianza post-commercializzazione e la vigilanza del mercato per i sistemi IA. - Qualità dei dati: gli sviluppatori dovrebbero valutare se i dati disponibili sono di qualità sufficiente per supportare lo sviluppo del sistema di IA per raggiungere lo scopo previsto. Inoltre, gli sviluppatori dovrebbero prendere in considerazione l’implementazione di rigorose valutazioni pre-rilascio per i sistemi di IA per garantire che non si amplifichino dei problemi, come distorsioni ed errori. Progettazione accurata o la risoluzione tempestiva dei problemi può aiutare a identificare tempestivamente i problemi di qualità dei dati e può prevenire o mitigare possibili danni che ne derivino. I portatori di interessi dovrebbero inoltre prendere in considerazione la possibilità di attenuare i problemi di qualità dei dati e rischi che emergono nei dati sanitari, nonché continuare a lavorare per creare ecosistemi di dati per facilitare la condivisione di fonti di dati di buona qualità.
- Privacy e protezione dei dati: la privacy e la protezione dei dati dovrebbero essere considerate durante la progettazione e la diffusione dei sistemi di IA. All’inizio del processo di sviluppo, gli sviluppatori dovrebbero prendere in considerazione l’acquisizione di una buona comprensione delle normative applicabili in materia di protezione dei dati e delle leggi sulla privacy e che il processo di sviluppo soddisfi o superi tali requisiti legali. È inoltre importante prendere in considerazione l’attuazione di un programma di conformità che affronti i rischi e garantisca che la tutela della Privacy. Le pratiche di cybersicurezza tengono conto dei potenziali danni e del contesto di applicazione.
- Coinvolgimento e collaborazione: durante lo sviluppo della tabella di marcia per l’innovazione e la diffusione dell’IA.
È necessario considerare lo sviluppo di piattaforme accessibili e informative che facilitino l’impegno e la collaborazione tra le principali parti interessate, ove applicabile e appropriato, così come è fondamentale prendere in considerazione la razionalizzazione del processo di sorveglianza per la regolamentazione dell’IA e la collaborazione al fine di accelerare i progressi che cambiano la pratica nell’IA.
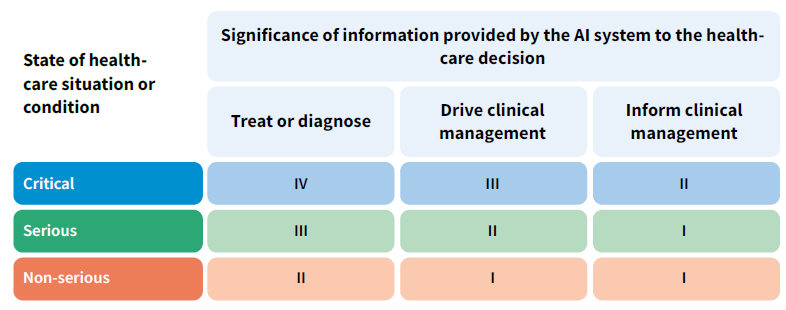
Il documento analizza anche i rischi in ambito sanitario dell’AI classificandoli come da immagine che segue:
Sempre sul tema è di certo interesse guardare all’Artificial intelligence in healthcare Applications, risks, and ethical and societal impacts[3] dell’EPRS (European Parliamentary Research Service), che riporta i 7 rischi che emergono in un sistema/agente di AI indicandone anche le misure di remediation (cui si rimanda):
- Danni al paziente dovuti a errori di intelligenza artificiale;
- Uso improprio degli strumenti di IA medica;
- Rischio di bias nell’IA medica e perpetuazione delle disuguaglianze;
- Mancanza di trasparenza;
- Problemi di privacy e sicurezza;
- Lacune nella responsabilità dell’IA;
- Ostacoli all’implementazione nell’assistenza sanitaria nel mondo reale.
L’analisi dei rischi dovuti all’AI viene, poi, affrontata anche dal RMF (Risk Management Framework) del NIST [https://www.nist.gov/itl/ai-risk-management-framework] che riporta, per le funzioni, le sottocategorie alle quali è necessario rispondere per avere una valutazione del sistema:
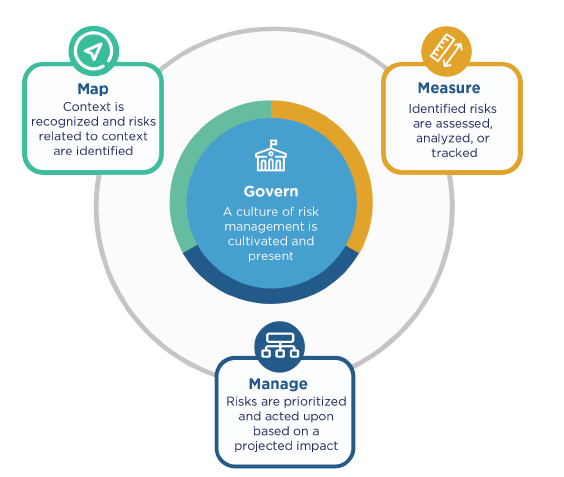
- la funzione GOVERN è suddivisa in 6 categorie e 13 sottocategorie. Questa coltiva e implementa una cultura della gestione del rischio all’interno delle organizzazioni che progettano, sviluppano, implementano, valutano o acquisiscono sistemi di intelligenza artificiale; delinea i processi, i documenti e gli schemi organizzativi che anticipano, identificano e gestiscono i rischi che un sistema può comportare, incorpora processi per valutare gli impatti potenziali; fornisce una struttura in base alla quale le funzioni di gestione del rischio dell’IA possono allinearsi ai principi, alle politiche e alle priorità strategiche dell’organizzazione; collega gli aspetti tecnici della progettazione e dello sviluppo dei sistemi di AI ai valori e ai principi dell’organizzazione e consente pratiche e competenze organizzative per le persone coinvolte nell’acquisizione, nella formazione, nell’implementazione e nel monitoraggio di tali sistemi; e affronta l’intero ciclo di vita del prodotto e i processi associati, comprese le questioni legali e di altro tipo relative all’uso di sistemi e dati software o hardware di terze parti;
- la funzione MAP è suddivisa in 5 categorie e 18 sottocategorie. La MAP stabilisce il contesto per inquadrare i rischi relativi a un sistema di IA. L’IA Il ciclo di vita è costituito da molte attività interdipendenti che coinvolgono un insieme diversificato di attori. In pratica, gli attori dell’IA responsabili di una parte del processo spesso non dispongono di visibilità o controllo su altre parti e sui loro contesti associati;
- la funzione MEASURE, invece, è composta da 4 categorie e 22 sottocategorie. Questa impiega strumenti, tecniche e metodologie quantitative, qualitative o miste per analizzare, valutare, confrontare e monitorare il rischio dell’IA e i relativi impatti. Utilizza le conoscenze relative ai rischi dell’IA identificati nella funzione MAP e informa la funzione MANAGE. I sistemi di IA dovrebbero essere testati prima della loro diffusione e regolarmente durante il funzionamento. Le misurazioni del rischio dell’IA includono la documentazione degli aspetti della funzionalità e dell’affidabilità dei sistemi;
- la funzione MANAGE, infine, è suddivisa in 4 categorie e 13 sottocategorie e comporta l’allocazione delle risorse di rischio a rischi mappati e misurati su base regolare e come definito dalla funzione GOVERN. Il trattamento del rischio comprende piani per rispondere, riprendersi e comunicare in merito a incidenti o eventi.
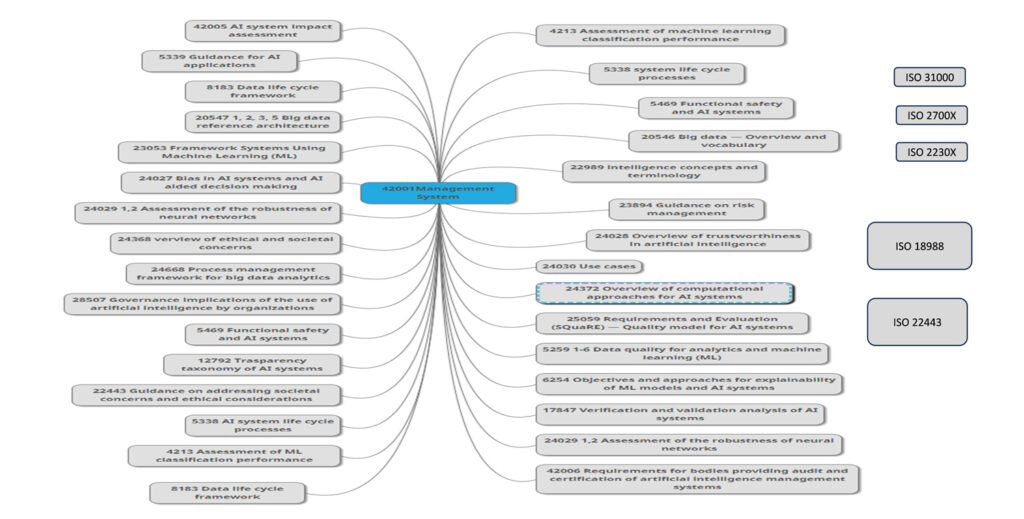
Senza dimenticare che, oltre ai documenti già citati, possono venire in aiuto anche le norme ISO dedicate all’AI, in primis quella relativa ad un sistema di gestione dell’AI – la norma(con i relativi controlli) -, e come supporto tutte le norme di contorno a partire dalla ISO 42005 relativa alla valutazione d’impatto, la ISO 23894 dedicata ai rischi, le norme ISO della serie 250XX dedicata alla qualità dei dati e del software oppure quelle relative alla gestione e validazione degli algoritmi di Machine Learning e le norme ISO 18988 (Applicazione delle tecnologie AI all’informatica sanitaria) e ISO 22443 (Guida su come affrontare le preoccupazioni sociali e le considerazioni etiche) che sono in fase di pubblicazione. Altre norme che possono aiutare a comprendere il sistema, i rischi e gli impatti sono la ISO 27001 sulla sicurezza delle informazioni, ISO 27005 sui rischi relativi alla sicurezza delle informazioni, ISO 31000 sulla gestione dei rischi e ISO 22301 sulla continuità operativa.
In ultimo, anche il Regolamento “AI Act” – caratterizzato da un risk-based approach – concentra buona parte dei propri sforzi sulla parte relativa ai rischi, considerando di “alto livello” quelli trattati nel presente contributo, e così:
“Articolo 6
Regole di classificazione per i sistemi di IA ad alto rischio
- Indipendentemente dal fatto che un sistema di IA sia immesso sul mercato o messo in servizio indipendentemente dai prodotti di cui alle lettere a) e b), tale sistema di IA è considerato ad alto rischio se sono soddisfatte entrambe le seguenti condizioni:
- a) il sistema di IA è destinato a essere utilizzato come componente di sicurezza di un prodotto, o il sistema di IA è esso stesso un prodotto disciplinato dalla normativa di armonizzazione dell’Unione elencata nell’allegato II;
- b) il prodotto il cui componente di sicurezza a norma della lettera a) è il sistema di IA, o il sistema di IA stesso in quanto prodotto, è tenuto a sottoporsi a una valutazione della conformità da parte di terzi, ai fini dell’immissione sul mercato o della messa in servizio di tale prodotto a norma della normativa di armonizzazione dell’Unione elencata nell’allegato II.
- Oltre ai sistemi di IA ad alto rischio di cui al paragrafo 1, anche i sistemi di IA di cui all’allegato III sono considerati ad alto rischio”.
In particolare l’allegato III cita:
“5. Accesso e godimento dei servizi privati essenziali e dei servizi e delle prestazioni pubbliche essenziali:
a) sistemi di IA destinati a essere utilizzati dalle autorità pubbliche o per conto delle autorità pubbliche per valutare l’ammissibilità delle persone fisiche a prestazioni e servizi essenziali di assistenza pubblica, compresi i servizi sanitari, nonché per concedere, ridurre, revocare o richiedere tali prestazioni e servizi”.
L’AI Act, oltre ai servizi, considera anche i prodotti e i dispositivi medici come indicato dal Regolamento UE 2017/745 del 5 aprile 2017 relativo ai dispositivi medici, i quali sono considerati oggetti ad alto rischio.
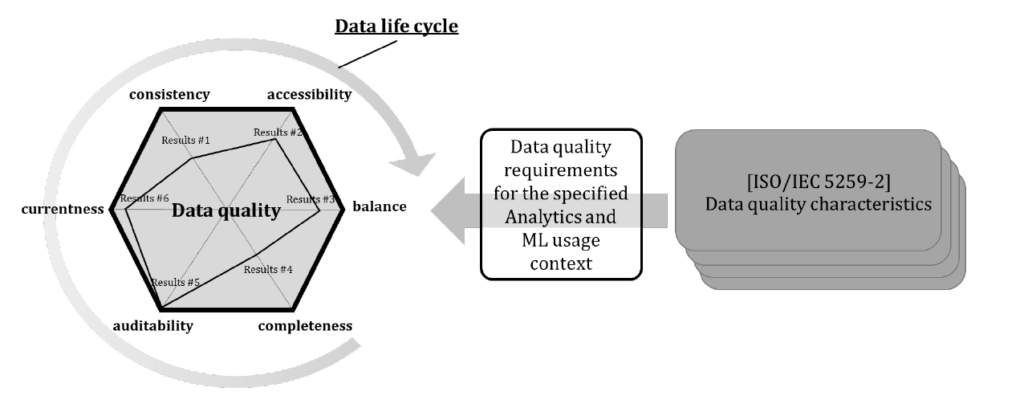
Nell’ambito sanitario, dove è importantissimo l’impatto sulla persona diventa fondamentale la conoscenza dei processi di Machine Learning, dalla qualità e correttezza dei dati, agli algoritmi utilizzati, alle metodologie e ai controlli.
Ad esempio:
- la qualità dei dati,
- i tipi di ML utilizzati: Supervisionato, non supervisionato e rinforzato (ISO 2053),
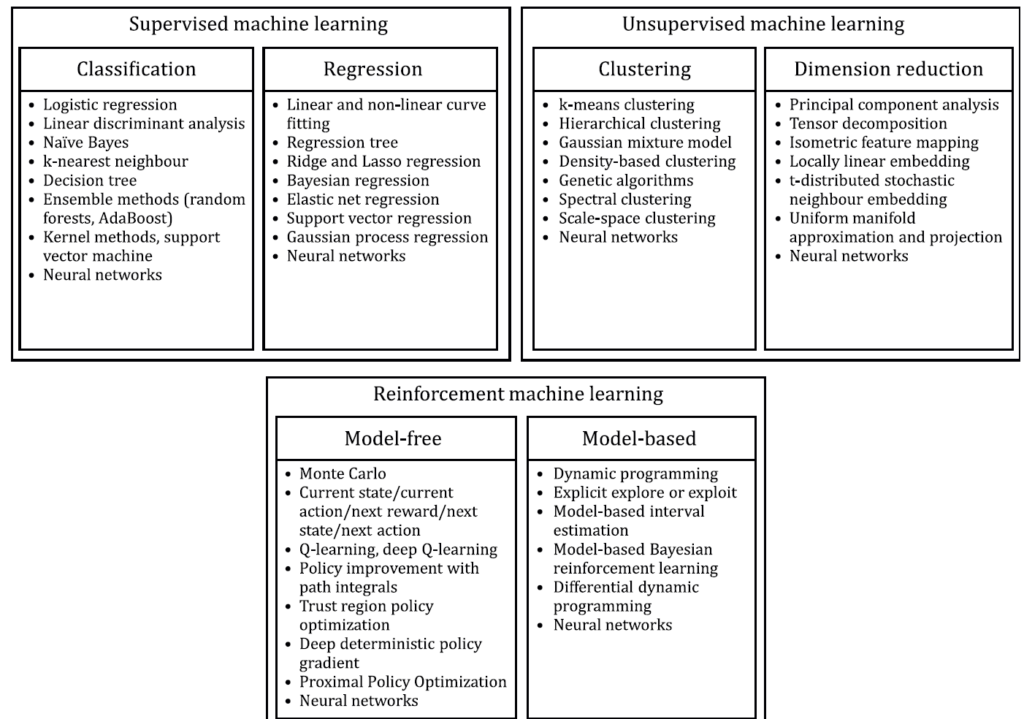
che risultano importanti per:
- Diagnosi della malattia
- Medicina personalizzata
- Produzione di farmaci
- Svolgimento dei test clinici
- Radioterapia e radiologia
- Raccolta elettronica dei dati
- Previsione delle epidemie
e i suoi controlli (dove T=vero, F=falso, P=positivo e N=negativo) come riportato dalla ISO TS 4213:

- oppure i tipi di AI:
- Intelligenza artificiale stretta (ANI), che ha una gamma ristretta di abilità, definita anche come debole o stretta;
- Intelligenza generale artificiale (AGI), che è alla pari con le capacità umane, definita anche come AI forte o profonda;
- Super intelligenza artificiale (ASI), che risulta più capace di un essere umano.
Allora, l’analisi e la riduzione dei rischi, dato l’elevato impatto sulle persone, diventa un’attività fondamentale e necessaria per una corretta applicazione e gestione dei sistemi AI.
Volendo, infine, scendere più nel concreto con riferimento all’applicazione pratica di Ai nell’ambito sanitario, è d’obbligo citare – seppur in estrema sintesi – il recente (marzo 2024) “Compendio sul trattamento dei dati personali effettuato attraverso piattaforme volte a mettere in contatto i pazienti con i professionisti sanitari accessibili via web e app” del Garante italiano per la protezione dei dati personali. Nello specifico, si tratta di un documento che fornisce indicazioni su come devono essere trattati i dati nei casi in cui il contatto tra medico e paziente avvenga attraverso una piattaforma o una app, ossia mediante strumenti innovativi che contengono sistemi di AI.
Il decalogo dei punti cui prestare particolare attenzione può essere riassunto come segue:
- finalità del trattamento,
- coordinamento con la disciplina vigente,
- basi giuridiche,
- divieto di diffusione dei dati e comunicazione di dati a terzi,
- valutazione d’impatto,
- ruoli privacy, adempimenti e responsabilità,
- principio di correttezza e trasparenza e informativa,
- trattamenti transfrontalieri,
- Privacy by Design,
- sicurezza del trattamento.
Per quanto qui d’interesse, si rileva che:
- con riferimento al punto 5, il trattamento rientra tra quelli ad alto rischio che richiedono obbligatoriamente la preventiva valutazione d’impatto ex 35 GDPR[4] e delle Linee Guida del Gruppo di Lavoro Articolo 29[5], al fine di comprovare l’idoneità delle misure di sicurezza applicate, tenuto anche conto degli specifici rischi connessi al trattamento effettuato,
- ex punto 9, i titolari del trattamento sono tenuti a trattare i dati personali solo utilizzando sistemi e tecnologie che integrano by design e by default i principi di protezione dei dati (cfr. considerando 78 del Regolamento e punto 94 delle citate Linee guida),
- ai sensi del punto 10, il gestore della piattaforma dovrebbe implementare misure di sicurezza adeguate e così, ad esempio:
- tecniche crittografiche durante la trasmissione dei dati su internet
- un protocollo di rete che garantisca la riservatezza e l’integrità dei dati scambiati tra il browser dell’utente e il server che ospita i servizi delle predette piattaforme, consentendo inoltre agli utenti di verificare l’autenticità del sito web visualizzato.
- una procedura di adesione alla piattaforma da parte dello specialista che preveda la verifica del possesso della qualifica professionale (es. invio di un codice OTP all’indirizzo PEC -censito su INI-PEC- del medesimo professionista);
- una procedura di verifica/convalida del dato di contatto scelto dall’utente (es. indirizzo di posta elettronica, numero di cellulare);
- misure volte alla riduzione degli errori di omonimia/omocodia;
- una procedura di autenticazione informatica a più fattori;
- meccanismi di blocco dell’app in caso di inattività o di chiusura della medesima;
- sistemi di monitoraggio, anche automatici, per rilevare accessi non autorizzati o anomali alla piattaforma.
Note
- [1] https://ec.europa.eu/commission/presscorner/detail/en/IP_18_3362.
- [2] Regulatory considerations on artificial intelligence for health, https://iris.who.int/bitstream/handle/10665/373421/9789240078871-eng.pdf?sequence=1&isAllowed=y.
- [3] https://www.europarl.europa.eu/thinktank/en/document/EPRS_STU(2022)729512.
- [4] Il GDPR introduce, infatti, l’obbligo per i titolari di svolgere una preventiva valutazione di impatto sul trattamento che “prevede in particolare l’uso di nuove tecnologie, considerati la natura, l’oggetto, il contesto e le finalità del trattamento, può presentare un rischio elevato per i diritti e le libertà delle persone fisiche”.
- [5] WP248rev.01, adottate il 4 aprile 2017 come modificate e adottate da ultimo il 4 ottobre 2017.
Articolo a cura di Stefano Gorla e Anna Capoluongo

Consulente e formatore in ambito governance AI, sicurezza e tutela dei dati e delle informazioni;
Membro commissione 533 UNINFO su AI; Comitato di Presidenza E.N.I.A.
Membro del Gruppo di Lavoro interassociativo sull’Intelligenza Artificiale di Assintel
Auditor certificato Aicq/Sicev ISO 42001, 27001, 9001, 22301, 20000-1, certificato ITILv4 e COBIT 5 ISACA, DPO Certificato Aicq/Sicev e FAC certifica, Certificato NIST Specialist FAC certifica,
Referente di schema Auditor ISO 42001 AicqSICEV.
Master EQFM. È autore di varie pubblicazioni sui temi di cui si occupa.
Relatore in numerosi convegni.

Avvocato Data Protection & ICT | Data Protection Officer UNI 11697 | membro dell’EDPB’s Support Pool of Experts | Membro Women For Security | Membro Osservatorio sulla Giustizia Civile Tribunale Milano (Gruppo sul danno da illecito trattamento dei dati personali) | Afferente B-ASC (Università Milano-Bicocca Applied Statistics Center) | Vicepresidente Institute for Research of Law Economical and Social Studies| Membro Gruppo di Lavoro sull’AI di ANORC | Docente a c. (Università di Padova, Sole24Ore Business School), Comitato di Presidenza E.N.I.A.