Adversarial Machine Learning – Aspetti Scientifici
L’Adversarial Machine Learning rappresenta uno degli ambiti più complessi e stimolanti nel contesto della sicurezza dei sistemi di machine learning. Questo campo si caratterizza per la necessità di comprendere e mitigare le diverse tipologie di attacchi che possono compromettere l’integrità, la sicurezza e l’affidabilità dei modelli di apprendimento automatico. Tali attacchi rappresentano una sfida significativa non solo per gli esperti di sicurezza, ma anche per i ricercatori e i praticanti del machine learning che devono confrontarsi con un panorama in continua evoluzione e ricco di nuove minacce.
Questo contributo si inserisce in un percorso di approfondimento che ha già esaminato diverse prospettive di tali attacchi, come discusso nei contributi precedenti sugli “Attacchi ai Modelli di Intelligenza Artificiale” e sugli “Adversarial Attacks a Modelli di Machine Learning“. Questi argomenti sono fondamentali per comprendere l’ampiezza delle vulnerabilità che caratterizzano i moderni sistemi di intelligenza artificiale e per valutare le possibili contromisure.
Adversarial Machine Learning: Gli Adversarial Examples sono vulnerabilità intrinseche ai modelli di machine learning
Gli Adversarial Examples, discussi nella sezione precedente, non costituiscono eventi di attacco diretti, ma rappresentano piuttosto vulnerabilità intrinseche ai modelli di machine learning che possono essere sfruttate da un avversario per manipolare i risultati ottenuti. Un Adversarial Example è una perturbazione accuratamente progettata, apparentemente insignificante per l’occhio umano, ma capace di indurre il modello a fare errori significativi. Questa capacità di indurre in errore un sistema ben addestrato mette in luce le carenze strutturali nella robustezza dei modelli, evidenziando la necessità di sviluppare strategie di difesa sempre più sofisticate. Analizzeremo come tali vulnerabilità possano essere sfruttate per aggirare i sistemi di machine learning, generando risultati imprevisti o potenzialmente pericolosi per l’integrità del modello, compromettendo così la sua affidabilità operativa.

Come per molti altri tipi di vulnerabilità dei sistemi IT, se questo modello ML fosse utilizzato in un sistema di controllo degli accessi, questa vulnerabilità potrebbe essere sfruttata da un attaccante per impersonare un’altra persona e accedere illegalmente a un sistema o servizio.
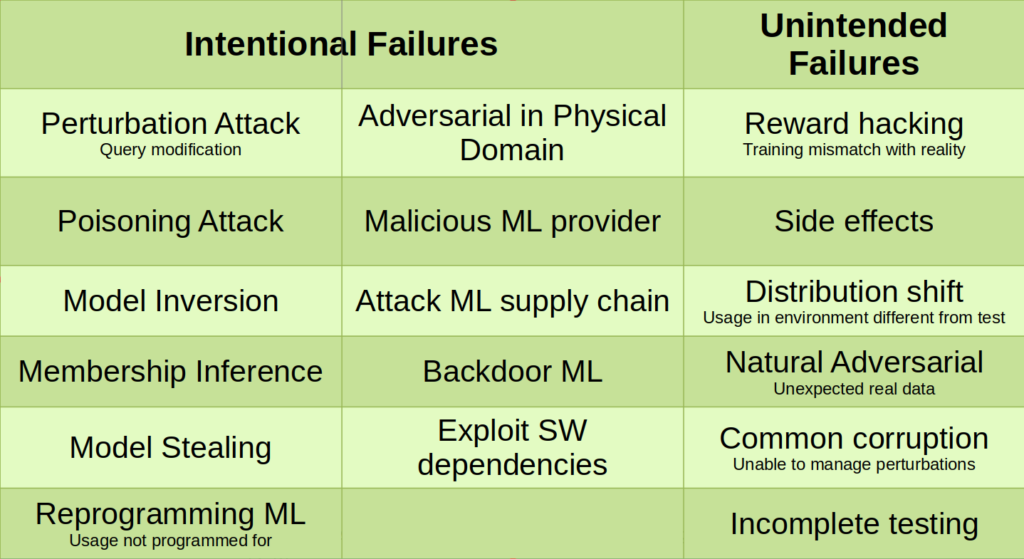
La presenza di Adversarial Examples non è l’unico tipo di vulnerabilità o l’unico modo per attaccare o abusare di un modello ML. Sono state proposte alcune tassonomie di attacchi e minacce ai modelli ML e in generale ai modelli di Intelligenza Artificiale, tra cui quella di Microsoft [Rif. 6] riassunta in Fig. 4 e quella di MITRE [Rif. 7], riassunta in Fig. 5.

Attacchi ai dati di addestramento
La qualità e integrità dei dati utilizzati per l’addestramento di un modello ML sono cruciali per ottenere il comportamento atteso. Per l’addestramento è inoltre spesso necessaria una grande mole di dati, spesso forniti da terze parti.
Come semplice esempio, si consideri il caso di un modello ML utilizzato per identificare messaggi di posta elettronica di SPAM. Un attaccante che vuole organizzare una campagna di SPAM è interessato ad evitare che i propri messaggi siano identificati come SPAM dal modello ML. Per far questo può cercare di inserire i propri messaggi nei dati di addestramento classificandoli come non-SPAM.
Oppure può cercare di accedere ai dati di addestramento e modificare la classificazione di alcuni di essi in modo che non risultino più classificati come SPAM. Gli esempi di SPAM che forniscono i dati di addestramento del modello ML sono di norma raccolti da molte sorgenti, per lo più pubbliche: può essere pertanto sufficiente che l’attaccante riesca ad attaccare una componente della Supply Chain per sovvertire o “avvelenare” (Poisoning) il modello ML.
La modifica dei dati d’addestramento fatta alla fonte, presso eventuali terze parti che raccolgono i dati o presso l’utente finale che addestra il modello ML, può portare ad esempio alla creazione di Backdoor quali comportamenti nascosti attivabili tramite particolari sequenze di dati in input, o di Bias (una distorsione o deviazione sistematica rispetto al risultato atteso) che possono permettere ad un attaccante di utilizzare il modello ML per i propri scopi.
Attacchi al codice dei modelli di Machine Learning
Anche piccole modifiche al codice o all’eseguibile di un modello di Machine Learning possono portare a introdurre comportamenti malevoli come quelli appena descritti. Molto spesso un utente di un modello ML non costruisce da zero il codice del modello ma ottiene un modello già costruito e pre-addestrato da un fornitore, per poi completare l’addestramento con i propri dati.
Un attaccante può quindi attaccare questa Supply Chain con l’intento di modificare il codice del modello ML in modo che questo, anche se ulteriormente addestrato, continui a presentare delle Backdoor, Bias o in generale dei comportamenti malevoli. Nel caso più semplice di un modello ML il cui codice sorgente è pubblico, l’attaccante può ottenere e modificare il codice, addestrare il modello ML e far sì, ad esempio tramite un’intrusione nel server che distribuisce il codice, che l’utente utilizzi il modello ML con il codice modificato.
Attacchi al modello di Machine Learning
In questo caso l’attaccante accede come utente ad un modello ML già addestrato per attaccarlo. L’attaccante può non avere alcuna informazione sul modello (attacco Black Box), qualche informazione sui dati di addestramento e/o sulla struttura del modello (attacco Grey Box), o completa informazione e disponibilità sia dei dati di addestramento sia del modello stesso (attacco White Box). In tutti i casi, l’attaccante non è in grado di modificare i dati di addestramento o il codice del modello sotto attacco se non interagendo con il modello ML stesso.
L’attaccante può quindi utilizzare direttamente il modello ML sotto attacco e analizzare i dati prodotti dal modello a seconda dei diversi input inviati al modello. Questo può permettere all’attaccante di identificare delle vulnerabilità del modello ML che possono permettergli di abusare del modello, ovvero ottenere dei risultati non previsti o a proprio favore (Inference e Model Evasion). Ad esempio l’attaccante può identificare e sfruttare a proprio favore dei Bias nel modello ML, oppure costruire degli Adversarial Examples come descritto precedentemente, o ancora identificare dei modi di utilizzo del modello ML non previsti e per i quali il modello ML non è stato specificatamente addestrato. Può essere utile presentare alcuni esempi teorici.
Riprendendo l’esempio precedente di un modello ML utilizzato per identificare messaggi di posta elettronica di SPAM, l’attaccante continua a modificare la formulazione del proprio messaggio sino a che il modello cessa di identificarlo come SPAM. Ovviamente in breve tempo i nuovi messaggi di SPAM non correttamente classificati dal modello ML vengono identificati manualmente, il che richiede un ulteriore addestramento del modello ML aggiungendo i nuovi campioni di SPAM.
Ciò porta, anche in questo caso, al ben noto ciclo di attività attaccante-difensore tipico di molti sistemi di sicurezza. Come indicato precedentemente, alcuni modelli ML hanno mostrato una vulnerabilità indicata come “smemoratezza” (Forgetfulness): ovvero il fatto che ulteriori aggiornamenti di un modello ML con nuovi dati di addestramento possono portare il modello ML a dimenticare informazioni precedentemente acquisite. Se questo succedesse nel presente esempio, una volta ulteriormente addestrato il modello ML non identificherebbe più alcuni messaggi di SPAM che prima identificava correttamente.
Un altro tipico caso di studio è quello di un modello ML a supporto del processo di erogazione di un mutuo, prestito o finanziamento. L’attaccante, utilizzando il modello, scopre che questo ha dei Bias e che alcune classi di richiedenti (identificati per gruppo sociale o geografico, etnia ecc.) sono favorite dal modello ML nell’ottenere l’erogazione a discapito di altre. L’attaccante può quindi formulare la domanda in modo da presentarsi al modello ML come parte di un gruppo favorito e quindi avere maggiori possibilità di ottenere il finanziamento, anche se in realtà non gli sarebbe dovuto.
Altri esempi sono i modelli ML a supporto dei sistemi di controllo accessi e videosorveglianza. Come descritto precedentemente, l’identificazione da parte di un attaccante di Adversarial Examples per un modello ML utilizzato a questi scopi può permettere all’attaccante di aggirare un sistema di controllo degli accessi o evitare di essere riconosciuto da un sistema di videosorveglianza.
Invece di abusare dei risultati di un modello ML, un attaccante può essere interessato al modello ML stesso: alla sua architettura, al suo codice sorgente e ai dati con cui è stato addestrato. Sempre interagendo con un modello ML, l’attaccante può quindi cercare di estrarre informazioni interne al modello stesso. Come esempio di questo tipo di attacco si può considerare non un modello ML per la classificazione di immagini ma un ChatBot come il famoso ChatGPT. Questi tipi di modelli ML interagiscono con l’utente e producono tipicamente testi o immagini.
Con opportune richieste al modello ML e analizzando le risposte ottenute, l’attaccante può dedurre e in alcuni casi ottenere copia di alcuni dati utilizzati per l’addestramento del modello, che possono anche essere riservati.
Alcuni di questi modelli ML apprendono anche dalle richieste e dalle interazioni con gli utenti; e analogamente un attaccante potrebbe venire a conoscenza di informazioni fornite in input al modello ML da un altro utente, in alcuni casi violandone la privacy. Sempre con opportune richieste al modello ML, l’attaccante potrebbe venire a conoscenza dell’architettura, configurazione e anche del valore di alcuni parametri. Si tratta quindi di attacchi il cui scopo è l’inversione del modello ML e/o l’estrazione o furto di informazioni dal modello stesso.
Infine alcuni di questi attacchi possono anche essere sfruttati per rendere il modello non operativo, nel senso che il modello non è più in grado di svolgere il compito per cui è stato costruito e addestrato. Ad esempio, nel caso di un modello ML per il riconoscimento di immagini o messaggi di posta elettronica di SPAM, il modello dopo l’attacco non riconosce più alcuna immagine o messaggio di SPAM. Si può quindi classificare l’effetto di questi attacchi come un particolare tipo di Denial of Service.
Vulnerabilità e Sicurezza Proattiva
Come già accennato all’inizio di questo articolo, per gestire la “sicurezza” dei modelli di Machine Learning è possibile adottare l’approccio usuale alla gestione della sicurezza IT (o Cyber-sicurezza). Anche se di tipo e con caratteristiche diverse, i modelli di ML e in generale di Intelligenza Artificiale sono applicazioni IT e, come tali, possono avere delle vulnerabilità specifiche che possono essere sfruttate da un attaccante.
Chi ne gestisce la sicurezza può quindi sottomettere a verifica queste applicazioni prima che siano messe in produzione per individuare l’eventuale presenza di queste vulnerabilità. Verifiche simili – in termini di approccio – a quelle svolte con i Penetration Test (o Red Teaming) per un’applicazione Web prima del rilascio in produzione, dovrebbero essere fatte anche per i modelli di Machine Learning al fine di identificare l’eventuale presenza di vulnerabilità quali quelle brevemente descritte in questo articolo.
Riferimenti Bibliografici
Rif. 5: M. Sharif, S. Bhagavatula, L. Bauer, M.K. Reiter, “Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition”, https://users.cs.northwestern.edu/~srutib/papers/face-rec-ccs16.pdf
Rif. 6: Microsoft “Threat taxonomy – Failure modes in machine learning”, https://learn.microsoft.com/en-us/security/engineering/
Rif. 7: MITRE “Adversarial Threat Landscape for Artificial-Intelligence Systems (ATLAS)”, https://atlas.mitre.org/
 Continua a leggere: scarica il white paper gratuito “Adversarial Attacks a Modelli di Machine Learning“
Continua a leggere: scarica il white paper gratuito “Adversarial Attacks a Modelli di Machine Learning“
Articolo a cura di Andrea Pasquinucci

PhD CISA CISSP
Consulente freelance in sicurezza informatica: si occupa prevalentemente di consulenza al top management in Cyber Security e di progetti, governance, risk management, compliance, audit e formazione in sicurezza IT.